A Comprehensive Overview of Sentiment Analysis: Evolution, Approaches, and Applications
Muskan Mahato1, Anjali1, Archana Negi1, Priya Bisht1, Makrand Dhyani1,*, Raj Kishor Bisht2 and Chandan Singh Ujrari1
1Department of Mathematics, Graphic Era Hill University, Dehradun, India
2School of Computing, Graphic Era Hill University, Dehradun, India
E-mail: muskanmahato88959@gmail.com; anjalimahar31@gmail.com; archananegi519@gmail.com; bishttpriya934@gmail.com; makdhyani23@gmail.com; bishtrk@gmail.com; ujarari0000@gmail.com
*Corresponding Author
Received 30 September 2025; Accepted 13 May 2026
Abstract
Sentiment analysis (SA) also known as opinion mining is a tool to determine the sentiments associated with linguistic data and is used by a variety of organisations over various domain. SA analysis has proved to be an effective tool at various business levels, organisational levels etc. Big companies, organisations, governments use social media platforms to identify the sentiments of the target audience in order to enhance their services and products. Current study is a chronological survey of SA, its applications and various approaches that were developed over the time for SA. This paper focuses on various SA techniques developed and their real-world applications. Details of SA, types of SA, terminology and approaches related and developed overtime are discussed at length. Applications and works related SA in domains related to social media, big business, and political campaigns are also discussed.
Table 1 List of abbreviations used
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| CNN | Convolutional Neural Networks |
| SVM | Support Vector Machine |
| NLP | Natural language processing |
| NLTK | Natural Language Toolkit |
| DT | Decision Tree |
| NN | Neural Networks |
| GA | Genetic Algorithm |
| PCA | Principal Component Analysis |
| LSA | Latent Semantic Analysis |
| GRU | Gated Recurrent Unit |
| FIP | Fuzzy Inference Process |
| ME | Machine Entropy |
| LBA | Lexicon Based Approach |
| BERT | Bidirectional Encoder Representations from Transformers |
| RRC | Review Reading Comprehension |
| SE | Sentiment Evolution |
| TF-IDF | Term Frequency, Inverse Document Frequency |
| BiGRU | Bidirectional Gated Recurrent Unit |
| CGC | Consumer Generated Content |
| SMO | Sequential Minimal Optimization |
Keywords: Sentiment analysis, subjectivity, polarity, support vector machine, NaiveBayes.
1 Introduction
SA is the application of NLP techniques to identify, classify and analyse emotions, attitude, sentiments behind the text. With ongoing boom in E-commerce and social media platforms, SA has been in trend and huge demand these days. Even the linguistic data generated on these daily platforms has been referred to as “big data” as it cannot be handled easily and large computational effective and accurate models are being developed to handle such data. Things like, sentiment mining, opinion extraction, emotion analysis come under the umbrella of SA. SA is used to do text analysis to see whether the overall attitude of the text in a statement, paragraph, document and corpus is positive, negative or neutral. It is also used to analyse and understand the emotions, opinion or attitude of a person for a topic or object. SA is find’s its vast applications businesses, e-commerce, social media, academics which are discussed at the later part of this survey paper.
SA is an application of NLP and is done through NLTK a python library to perform various projects. VADER, Text Blob, IBM Watson Natural Language Understanding, Google Cloud Natural Language API, Azure Text Analytics, and Stanford CoreNLP are some available open-source libraries for SA. Where all these tools have some different approaches or languages to obtain the sentiments but all helps in various ways. Table 2 breifely describes the various concepts and terminologies used in SA.
Table 2 Terminology in sentiment analysis
| S. No. | Term | Definition | Approach | Uses |
| 1. | NLP | NLP combines computational linguistics, ML and DL models to process natural language. Computational linguistics includes development of models related to natural languages through computers and softwares. | Statistical Approach, Symbolic Approach, Connectionist Approach. | Large scale corpus analysis, Identifying Customer behaviour and satisfaction, accurate, effective, fast and objective analysis. |
| 2. | NLTK | It is an API for NLP with Python, preprocessing and further analysis of text data. | Importing Necessary Modules, Importing Dataset, Data Preprocessing and Visualization, Model Building. Prediction. | Tool for descriptive and detailed analysis of text corpora and NLP models. |
| 3. | Sentiment Analysis | Used to determine patterns and overall tone of the text, usually positive, negative, or neutral. | Rule-based, Automatic, Hybrid systems. | Used by various organisations for feedback and improvement of products and services. |
| 4. | Lexicon | Lexicon could be considered as some set of features having a predefined sentiment value. It includes lists of words (lexicons or dictionaries) linked to different emotions to label the words. | Dictionary based approach, Corpus based approach. | Used to detect sentiments in text analysis. |
| 5. | Machine learning | Enabling machines to learn (predict) from tasks based on previous experience (data). | Knowledge acquisition, supervised learning, unsupervised learning and reinforcement learning. | ML models are being extensively used in businesses which include services related to fraud detection, security, personalization, recommendations especially on OTT platforms, automated customer service through chatbots, transcription and translation, data analysis and more. |
| 6. | Hybrid Techniques | Combination/ Collaboartion of two or more different methodologies/algorithims. | Various ML based techniques. | These models can deal with complex scenarios more efficiently, reducing computational load. |
| 7. | Deep Learning | Deep learning is a crucial instrument in field of artificial intelligence (AI) that gives machine thae ability to think like humans. Deep learning models are highly useful in problems related to pattern recognition. | Neural networks, rule-based techniques. | Deep learning recognizes images, speech, and also processes natural language. It is widely used for digital assistants, voice-enabled devices and remote controls. It facilitates detecting fraudulent actions, self-driving cars, and generative AI. |
| 8. | Polarity | It is referred to as degree of emotions expressed in a sentence. | NaivesBayes. | Polarity is the overall sentiment conveyed by an individual text, sentence or document. polarity is usually expressed as “sentiment score”. |
| 9. | Subjectivity | Subjectivity quantifies the amount of personal opinion and factual information contained in the text. The higher subjectivity means that text is more opiniated rather than being factual. | NaivesBayes. | Social Media Monitoring, Human Resources, Market Research, Healthcare and Patient Feedback, Opinion Mining in News and Blogs. |
| 10. | Corpus | Corpus word is used to say for a bunch of documents and corpus-based analysis analyses the sentiment of a bunch of documents al together. | Corpus-based sentiment analysis involves analyzing and determining the sentiment expressed in a collection of text (a corpus) using computational methods. This technique leverages a large dataset of text to train machine learning models or apply linguistic rules to identify sentiment. | Election Predictions: Using sentiment trends to predict election outcomes and voter behavior. Trend Analysis: Identifying trends and public opinion on various topics by analyzing social media posts. Automated Support: Developing chatbots, virtual assistants that could detect and respond appropriately to customer emotions. |
1.1 Earlier Works on SA
The works related to NLP tasks and SA can be traced to 60’s and mid 70’s. Karlgren et al. (1994) used discriminant analysis for text classification and using a model named brown corpus. Kessler et al. (1997) proposed theory of genera’s for computational modelling of linguistic corpuses. Wiebe (2000) used clustering of words for subjectivity tagging. Turney (2002) presented a simple unsupervised learning algorithm for classifying reviews as recommended (thumbs up) or not recommended (thumbs down). Pang Lee and Vaithyanathan (2002) compared various ML techniques including NaivesBayes and SVMs for sentiment classification. Morinaga et al. (2002) used linguistic and syntactic rule-based techniques on huma- test samples to extract opinions off the internet. The term SA was first used by Nasukawa and Yi (2003). The paper focused on finding local statements on sentiments rather than analysing opinions on overall favourability and suggested it is better to analyse sentiments by breaking the document into individual smaller entities (text fragments that denote a sentiment about a subject) rather than considering or classifying the whole document as positive or negative. The term opinion mining was first used by Dave and Lawrence and Pennock (2003). Turney and Littman (2003) introduced a method for inferring the semantic orientation of a word from its statistical association with a set of positive and negative paradigm words.
Mullen and Collier (2004) introduced an approach towards SA using SVMs to collect diverse sources of related information such as favorability measures for phrases and adjectives. Whitelaw et al. (2005) extracted and analysed and appraisal groups such as “very good” or “not terribly funny”. Nadeau et al. (2006) automated analysis of sentiments in dreams by taking 100 dreams sampled from a dream bank. Pang and Lee (2008) covered promising techniques and approaches to directly enable opinion-oriented information-seeking systems. Wilson et al. (2009) developed a system that could automatically differentiate among contextual and prior polarity, with an emphasis on understanding the features that are significant for this task.
The rest of paper is organised as follows. Section 2 deals with types of SA and recent researches in the specific domain. Section 3 is the detailed analysis of approaches towards SA Section 4 discusses the real-world application of SA in various industrial sectors. The research is concluded in Section 5 followed by references in Section 6.
2 Types of Sentiment Analysis
SA can be done at various levels namely, sentence level, paragraph level, document level and corpus level. Sentence based analysis analyses each sentence of a long text and checks whether it is positive, negative or neutral. It’s used to give the positivity, negativity and neutrality of each sentence in a text. For example in a review or feedback, it analyses the text sentence by sentence. This helps to understand feelings and emotions of the person in each sentence from a long text. A sentence level machine learning approach for sentiment classification was developed by Khan et al. (2010) to analyze online reviews by extracting subjective sentences from the and labelling each sentence either positive or negative using NaïvesBayesian classifier. Trilla and Alias (2012) evaluated the different combinations of textual features and classifiers to recognise the most suitable adaptation procedure using Semeval 2007 dataset and a Twitter corpus.
Paragraph-based SA analyses the sentiment of each paragraph in the text. This approach is useful for longer texts where sentiment may vary within different sections. It only analyses a whole paragraph and classifies it as positive, negative or neutral. This helps to analyse the sentiment of a paragraph and to know it’s directed attitude, emotions or feelings. Ferguson et al. (2009) examined how additional information from paragraph-level annotations could add to the accuracy of document-level sentiment classification. O’Hare et al. (2009) proposed text extraction techniques to develop topic-specific sub-documents and thus training a sentiment classifier demonstrating a significant improvement in over full document classification. Authors concluded that the word-based approaches are better performing than paragraph-based or sentence-based approaches. A network-based features was proposed by De Arruda et al. (2019) to analyse the Voynich manuscript, compatible with real texts as per considered characteristics. Ke and Chan (2021) proposed Multilayer Content-Adaptive Recurrent Unit (CARU) network for paragraph information extraction.
Document level analysis analyses the overall document as positive, negative or neutral deals with overall tone of the document rather than breaking the document into paragraphs of sentences and then analysing them. It gives an overview of the literal attitude of the document. As length of a document could range from a single page to thousands of pages, document-level SA is challenging task compared to word or sentence-based SA which leads to an abundance of words and opinions, at times contradictory, in the same document. Document level analysis is usually done with articles related to press, specific products or posts related to an organisation. This type of analysis requires a high concentration, particularly when the topic of interest is sensitive in nature. Given a document as an input, Tang (2015a) proposed a learning research framework based on the available textural information to automatically classify its sentiment/opinion (thumbs up/ thumbs down).
Corpus word is used to say for a bunch of documents and corpus-based analysis analyses the sentiment of a bunch of documents all together. It helps large businesses and organisations to analyse data’s sentiments, emotions and feelings of the overall documents. Abdulla et al. (2013) built a manually annotated dataset and that takes the reader through the detailed steps of building the lexicon. Moreno-Ortiz and Fernández-Cruz (2015) proposed a 3-step model based on weirdness ratio to extract candidate terms from specialized corpora, later matched against general-language polarity database in order to obtain sentiment-bearing words whose polarity were domain-specific. Chathuranga et al. (2019) tested a POS tagged word corpus and the resultant sentiment lexicon was used to perform a lexicon based sentiment analysis of accuracy of three different classifiers. Researchers suggested that the developed framework could be more accurate with potentially larger text corpuses. Rice et al. (2021) demonstrated the validity of “minimally-supervised” approaches for the development of a sentiment dictionary from a corpus of text drawn from a specialized vocabulary. Figure 1 gives a detailed explanation of types and approaches towards SA.
3 Approaches Towards Sentiment Analysis
3.1 Lexicon Based Approach Towards SA
The lexicon-based approach is one most commonly used approach towards SA. The first work on lexicon-based approaches was presented by Turney (2002) in which two arbitrary words were used to compute the semantic orientation of a sentence. Nasukawa et al. (2003) extracted sentiment-associated polarity of positive or negative for specific subjects from a document, instead of classifying the whole document into positive or negative. Kanayama and Nasukawa (2006) proposed an unsupervised lexicon-building method for detecting positive or negative aspects in a specific domain. Work of Cao Q et al. (2011) utilized Lexicon based SA to discover semantic qualities from audits to examine the impact of different variables which may influence the supportive voting design for audits.
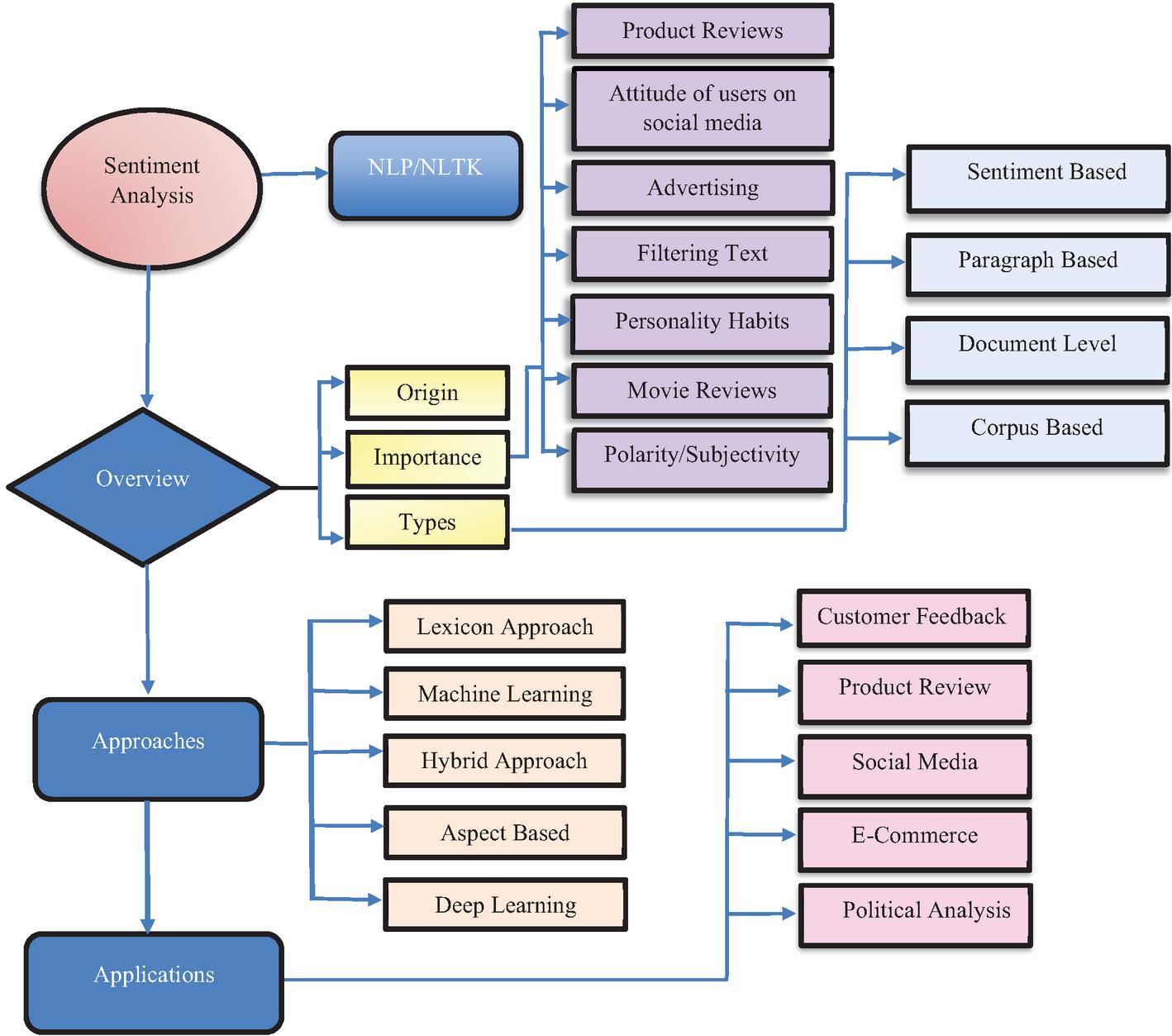
Figure 1 Sentiment analysis: Types and approaches.
Taboada et al. (2011) designed a method of dictionary creation along with use of mechanical Turk to check dictionaries for consistency and reliability. Pandarachalil et al. (2015) presented an unsupervised approach to SA specifically designed for large-scale Twitter data by using SenticNet, SentislangNet and SentiWordNet.
Park S et al. (2016) proposed a rule-based tactic for labelling feelings sentences and terms in situational commercials using a dictionary-themed method. Basiri et al. (2017) compared four lexicons to show the importance of lexicons in the performance of document-level sentiment analysis. Taj et al. (2019) did the SA of news using the dataset from BBC by using corpus based method of lexicon approach. Sallam et al. (2022) extended their efforts to improve the accuracy of Arabic collaborative filtering by applying SA to user reviews. Catelli et al. (2023) used NLP and SA to get insight into sentiments and opinions toward COVID-19 vaccination in Italy and the results highlighted an overall negative sentiment.
3.2 Machine Learning (ML) Based Approaches Towards SA
ML algorithms are applied to opinion documents and reviews in order to learn underlying patterns and other aspects thus capturing the sentiment of the document in question. The learned model can be applied to real-time social media data to assess people’s opinions about a particular company. Sentiment analysis is primarily modelled as a supervised learning problem. Therefore, manually labelled training data is required to build the initial model.
Mullen et al. (2004) introduced an approach to sentiment analysis by using SVM to bring together various sources of potentially pertinent information. Wilson et al. (2005) created a system which was able to automatically identify the contextual polarity for a large subset of sentiment expressions and the results were significantly better than the baseline. Begg et al. (2005) investigated SVM, an application of ML approaches, for the automatic recognition of gait changes due to spatial, kinetic and kinematic gait measures. Rani et al. (2006) presented a comparative study of different ML methods applied to the field of emotion recognition using physiological signals. Chau and Chen (2008) used ML based approaches to combine web content and structure analysis to filter out irrelevant documents from the data collected from the web. Muller et al. (2008) reviewed preprocessing and classification techniques for effective EEG-based mental state monitoring application and focused on Berlin based-computer interface (BBCI) which can be operated with minimal subject training. Melville et al. (2009) trained ML model by set of statements annotated as positive, negative or neutral for SA of blog and forum texts found on the World Wide Web, written in English, Dutch and French.
Nanli et al. (2012), Vinodhini and Chandrasekaran (2012) conducted a survey on the development, techniques, methods, research, challenges and application of SA in various domians. Gonçalves et al. (2013) developed a method combining approaches towards SA providing the best coverage results and competitive agreement along with a web service called iFeel, which provides an open API for accessing and comparing results across different sentiment methods for a given text. Agarwal and Mittal (2013) applied Rough Set Theory based feature selection method for sentiment classification. Neethu and Rajasree (2013) analysed twitter posts about electronic products using ML. Hovy (2015) provided examples of real-world usage of ML models and concluded the study with some suggestions, that how computational studies could address the problem in a more informed way. Pawar et al. (2016) explored text classification and feature classification with mathematical treatment.
An upgraded version of NaïveBayes algorithm, SentiRobo was presented by Rohani and Shayaa (2015) to predict the sentiment polarity of large data sets in social media. Mittal et al. (2016) combined Naïve Bayes and Decision Tree based ML algorithms to propose a flexible, fast and secure text analysis framework using apache spark. Hausler et al. (2018) tested various sentiment analysis measures for the text-based sentiment analysis in real state by utilising trained SVMs.
Kabir et al. (2021) compared and studied the performance of various techniques of ML approaches on online user reviews that came from multiple indsurtry domains and concluded that boosting and maximum entropy detected sentiments of online users better than the other examined ML algorithms. AlBadani et al. (2022) presented an effective model of SA using deep learning architectures by merging “universal language model fine-tuning” (ULMFiT) with SVM which increased the detection accuracy and efficiency.
3.3 Hybrid Approaches in SA
A hybrid approach in SA combines different methods or techniques, such as lexicon-based, machine learning, or rule-based approaches, to analyse sentiment in text. Mittal et al. (2013) proposed a three-stage hierarchical model for sentiment extraction, first labelling with emoticons followed by tweets labelling using lexicons with strong positive or negative sentiments and tokenizing weights based on subjectivity. Malandrakis et al. (2013) used a lexicon automatically generated from a large corpus of raw web data and calculated statistics over a NaïveBayes tree model. Also, a lexicon-based model is combined with a classifier built on maximum entropy language models, trained on a large external dataset. The hybrid classification method proposed by Govindarajan (2014) is based on coupling classification methods using arcing classifier along with classifier ensemble designed using NaïveBayes and SVM. The study is concluded with a comparative study of the effectiveness of ensemble technique for sentiment classification.
Mukwazvure and Supreethi (2015) developed a hybrid approach for SA of news comments which involves using sentiment lexicon for polarity detection (positive, negative and neutral). The method by Appel et al. (2016,2018) used fuzzy sets and a sentiment lexicon enhanced with the assistance of SentiWordNet, to predict the semantic orientation polarity and its intensity for sentences providing a foundation for computation of sentiments. The hybrid system outperformed NaïveBayes and ME in terms of precision and accuracy concluding the superiority of the developed model, when applied to SA problems at sentence level. Nandi and Agrawal (2016) combined the Lexical Dictionary based approach with the features of SVM learning classifier. Altaher (2017) proposed a hybrid approach for SA of Arabic tweets based deep learning techniques. And compared performance of the developed model with standard classification methods such as NN, DT, and SVM.
Al Amrani et al. (2018) used SVM and random forest, introducing a hybrid approach to identify product reviews and concluded that Random Forest merged with SVM algorithm were better performing than the other algorithms for product reviews. Iqbal et al. (2019) proposed a GA-based feature reduction technique using PCA and LSA for SA framework. Alharbi and Alhalabi (2020) proposed a hybrid approach of dictionary-based FIP algorithm which uses using fuzzy systems to accurately identify the sentiment of the input text and also addressed the challenges of SA using various fuzzy parameters. Mendon et al. (2021) developed a framework to analyse users’ sentiments by combining ML, statistical modelling, LBA, TF-IDF and K-means for sentiment classification among affinitive and hierarchical clustering. An ensemble model developed by Tan et al. (2022) comprised a combination of three hybrid deep learning models namely Robustly optimized BERT approach, LSTM, Bidirectional LSTM and GRU. Kaur and Sharma (2023) analysed sentiments through sentiment classification, feature extraction and LSTM. Ramirez-Alcocer et al. (2024) combined CNN and LSTM network to classify people’s sentiments on some particular topic.
3.4 Aspect Based Sentiment Analysis (ABSA)
ABSA is used to identify particular aspects or characteristics discussed in a text and assess the sentiment linked with each of these aspects. Varghese and Jayasree (2013) applied NLP for quantitative analysis of individual aspects using SVM classifier. Pavlopoulos (2014) decomposed the process of ABSA into 3 parts: term aggregation, term extraction, and term polarity estimation respectively. Che et al. (2015) enhanced ABSA by adding a sentiment sentence compression (Sent_Comp) step before performing the ABSA. Ruder et al. (2016) demonstrated the task of ABSA by modelling the interdependencies of sentences in a review with a hierarchical bidirectional LSTM.
De Clercq et al. (2017) introduced and tested integrated ABSA for Dutch language that included user feedback from three domains: human resources, retail, and banking through aspect polarity classification, aspect category classification and aspect term extraction. Ma et al. (2018) targeted ABSA by focusing on commonsense knowledge in deep neural sequential model and performed a joint task combining targeted aspect-based polarity classification and target-dependent aspect detection. Xu et al. (2019) first build a RRC dataset for ABSA and explored a new post-training approach on BERT. Phan and Ogunbona (2020) built a ABSA solution by part-of-speech embedding’s, dependency-based embedding’s and contextualized embedding’s and also introduced the concept of syntactic relative distance. Nazir et al. (2020) emphasized on extraction of relational mapping between aspects, interactions, relevant sentiments, contextual-semantic relationships and dependencies, between different data objects for improved sentiment accuracy.
Wang et al. (2021) categorized ABSA into two basic steps: aspect extraction and sentiment classification. A new taxonomy for ABSA organising studies from the concerned sentiment elements giving the utilization of pre-trained language models for ABSA systems in cross-domain scenarios was given by Zhang et al. (2022). Chauhan et al. (2023) focused on two primary subtasks, aspect extraction and aspect category detection of ABSA methods using deep learning and demonstrated a thorough evaluation of aspect extraction methodologies. Zhao et al. (2023) proposed a multitask learning model that could extract aspect terms, classify aspect polarity using multihead attention to associate dependency sequences with aspect extraction. Alqaryouti et al. (2024) proposed an ABSA hybrid approach integrating domain lexicons and rules to analyse apps reviews. The approach adopted language processing techniques, rules, and lexicons to address several SA challenges producing summarized results.
3.5 SA Through Deep Learning Models
Deep learning is a part of ML that allows a program to instruct itself to perform tasks like speech and image recognition and make neural network to automatically discover detection. Deep learning models operate by processing sequential text data and identifying complex relationships between words, phrases, and sentence structures.
The recent evolution of deep learning has transformed SA by enabling automated extraction of semantic, syntactic, and emotional features directly from raw text. Unlike traditional machine learning methods that depend heavily on handcrafted features, deep learning models can learn hierarchical text representations capable of capturing subtle linguistic and contextual patterns. Techniques such as CNNs, LSTM networks, and Transformer-based architectures like BERT have established new standards in accuracy and performance across various NLP applications. CNNs are among the earliest neural models applied to text classification. They utilize convolutional filters to extract local textual features and recognize sentiment indicators from n-gram patterns. As proposed by Kim (2014), CNNs are computationally efficient and well-suited for tasks such as short-text or microblog sentiment analysis. However, since CNNs focus mainly on local dependencies, they may fail to retain long-term contextual information within extended text segments.
To overcome this, LSTM networks, introduced by Hochreiter and Schmidhuber (1997) were designed with gated memory cells that store information over longer sequences. This architecture is particularly effective for modeling dependencies in lengthy reviews, comments, or conversational data. LSTM models mitigate the vanishing gradient problem common in traditional recurrent neural networks, making them robust for sequential sentiment tasks. Their ability to preserve sentiment flow across paragraphs gives them an edge in applications requiring context continuity.
The next major innovation was the development of Transformer-based architectures, which completely replaced sequential recurrence with a self-attention mechanism. The BERT model proposed by Devlin et al. (2019) processes text bidirectionally – analyzing both preceding and succeeding word contexts simultaneously. This feature allows BERT to accurately interpret complex sentiment expressions such as irony and negation. Its successors, including RoBERTa, DistilBERT and ALBERT by Liu et al. (2019) further optimize training efficiency, data utilization, and contextual embedding strength. These models dominate benchmark datasets such as IMDb, Yelp, and Amazon Reviews, surpassing traditional approaches in precision and robustness. Tang et al. (2015b) provided an overview of the successful deep learning approaches for SA tasks, challenges related to SA and provided some suggestions to address these challenges. Hassan et al. (2017) proposed CNN architecture that employs CNN and LSTM on top of pre-trained word vectors. Ciftci et al. (2018) compared logistic regression and NaiveBayes with RNN using LSTM units on a dataset of shopping and movie reviews in Turkish. Kaur et al. (2018) explained the SA, its levels and different approaches used for SA.
Ghorbani et al. (2020) integrated architecture of CNN and LSTM network to identify the polarity of words on the Google cloud. Lagrari and Elkettani (2021) reviewed classical and deep learning models applied to various SA tasks and their evolution over the recent years and also provided performance analysis of different SA models on particular datasets. Sunitha et al. (2022) analysed the real time tweets and did the feature extraction using TF-IDF, GloVe, pre-trained Word2Vec, and fast text embedding’s. A systematic literature review of deep learning methods for document-based SA to determine different features in the text can be found in the work of Alshuwaier et al. (2022).
Recent studies highlight the rise of hybrid deep learning models that integrate CNNs and LSTMs or combine BERT with lexicon-based sentiment resources to enhance both accuracy and interpretability. Hybrid models are especially valuable when dealing with domain-specific sentiment, where linguistic nuances vary widely across sectors like healthcare, finance, and politics.
Despite their exceptional accuracy, deep learning methods present notable challenges. They require extensive labeled datasets and substantial computational power, often relying on GPU or TPU resources. Researchers are therefore exploring Explainable AI (XAI) frameworks and lightweight neural models to reduce complexity and improve transparency. Table 3 highlights the key features, advantages and limitations of some deep learning models while Table 4 gives an overview of the practicality of approaches towards SA.
4 Overview of Sentiment Analysis in Various Domains
SA is an important tool which used to analyse how people’s feel and think about something such as products, objects and about someone. SA gives text analysis of emotions and feelings by providing it’s polarity, subjectivity, positivity, negativity and neutral in numerical form. It is used in various domains which are discussed in the following paragraphs. SA is used in businesses to know the public opinions for their products and services. Big e-commerce giants such as Amazon and Flipkart take reviews, ratings and feedback from customers to know and understand what customers desire and expect from their products and services.
Table 3 Advantages and limitations of some Deep Learning models in relation to SA
| Model/ | Type of | |||
| Architecture | Network | Key Features | Advantages | Limitations |
| CNN (Convolutional Neural Network) | Feed-forward neural network | Detects local word patterns and sentiment phrases using convolution filters | Fast, simple, suitable for short texts | Limited ability to capture long-term dependencies |
| LSTM (Long Short-Term Memory) | Recurrent neural network | Utilizes gating units to store and manage sequential information | Captures longterm sentiment patterns | High computational cost, slow training |
| BERT (Bidirectional Encoder Representations from Transformers) | Transformer-based | Enhanced BERT with better masking and training optimization | More accurate across multiple domains | Fine-tuning and training are resource-intensive |
| RoBERTa (Robustly Optimized BERT Approach) | Combination model | Integrates contextual and linguistic knowledge | Balances interpretability and performance | Model tuning is complex |
| Hybrid (CNN + LSTM or BERT + Lexicon) | Combination model | Integrates contextual and linguistic knowledge | Balances interpretability and performance | Model tuning is complex |
Suppose, a customer leaves a positive review on amazon saying “I like this headphone it’s good as shown” while the other one writes “the headphone is not so good and it’s volume system is not so good and not worth of money”. Both the reviews are opposite in nature as one is positive while other one is negative. Examining reviews and comments systematically through SA, companies improve their product quality by identifying the gaps in their products and services and thus amplifying an overall better customer experience.
Table 4 Practical comparison of approaches towards SA
| Data | Computational | ||||
| Approach | Accuracy | Requirement | Cost | Advantages | Limitations |
| Lexicon-based | Moderate | Low | Low | Simple, interpretable, suitable for small datasets | Poor performance on sarcasm and slang |
| Machine Learning (ML) | High | Medium | Medium | Learns from data and adaptable to new domains | Requires feature engineering and labeled data |
| Deep Learning (DL) | Very High | High | High | Captures deep semantic context and emotional tone | Computationally expensive, needs large datasets |
| Hybrid | Very High | High | High | Combines strengths of ML and Lexicon methods | Difficult to train and interpret |
Jagdale et al. (2019) suggested that SA plays a vital role in enabling the businesses to work actively on improving the business strategy and gain an in-depth insight of the buyer’s feedback about their product. SA could be extensively used in knowing opinions of a mass of people (at community, national or international level) as well as a person’s individual sentiments through analysing their social content and habits. People give different views at their posts and messages and their inclination towards several generalized moods such happy, sad aggressive, excited or worried can easily be predicted, identified and classified.
For example, during big events such as Olympics, SA can show us how fans are feeling by looking their posts. As if they are saying “wow what a game!, it enlighten my mood”, they are happy and excited. Whereas when Covid-19 pandemic hit the globe, it could be verified by online posts that people’s were worried and anxious. Although it is easy for one to identify and visualize the sentiments of an individual through his online posts, but when the number increases significantly, SA comes into picture. SA helps to understand sentiment and various emotions of people’s through mood of mass and individual on social media. Beigi et al. (2016) explored the applications of SA and demonstrated how sentiment mining in social media can be used to understand how local public mass reacts during a disaster, and whether or not, such information can be used to improve disaster management. Babu et al. (2022) presented an overview of sentiment analysis on Social media data for identifying apprehension or sadness through the use of different artificial intelligence methods.
SA alsos help to analyse the sentiment of persons which directly show or represent their personality. If a person is optimistic then his online posts would mostly be positive and happy and if a person is negative, his post would rather be more complaining in nature most of the time. Also, if a person like food they will used to posts different foods at different places and if a person like travelling they will posts the world’s corners where they travelled. Different people’s show their personality and habits through their posts by which we be able to know through sentiment analysis what’s the personality habits of individuals through their posting habits. Qi and Costin (2019) investigated the influence of habits of users by conducting SA on SMD in transportation field. Using keywords in social media search, Lubis et al. (2020) designed a step wise framework that aims to understand users’ habits by analysing their social media data.
SA is also valuable tool for advertisement. It measures the effectiveness of advertising campaigns and predicts how customers will perceive products and whether they’ll give positive or negative reviews about them. By analysing customer feedback, advertisers can identify which aspects of their campaigns work best and which need improvement.
SA is also used for analysing large amounts of data to determine whether the opinions and emotions expressed are positive, negative, or neutral. It helps to remove abusive language from text by automatically detecting and deleting hateful content before it reaches online users. Sai Nikhita et al. (2020) used NLP, Sentiment calculation and topic detection to detect the bad/vulgar/inappropriate comments not related to the specific context. Abdou et al. (2021) proposed a SA approach classifying social media posts into three categories namely hate, abusive and neutral respectively. The approach is based on a constructed dataset which reduces unbalancing and improves classification results.
Subjective language encompasses personal feelings, opinions, or judgment, while objective language comprises factual information. SA can separate objective and subjective data within a large dataset, allowing organizations to analyse it based on their requirements. It also assists in sorting the data based on subjectivity and objectivity, enabling users to access subjective data to understand public opinions on a specific topic. Montoyo et al. (2012) surveyed the state of research in the NLP tasks of subjectivity and SA, as well as their application domains closely-related research field of emotion detection. According to Li (2013), every consumer review has two views: subjective view and objective view. The subjective view of a consumer review reflects the opinions expressed by opinion words, while the objective view is constructed by the remaining text features.
Wang et al. (2013) focused on the importance of sentiment words in financial reports and financial risk. Agarwal et al. (2015) proposed a novel SA model that extracted common sense knowledge from ConceptNet based ontology and context information. Tang et al. (2015) aimed at identifying, extracting and organizing sentiments from user generated texts in social networks, blogs or product reviews. Kumar et al. (2016) focused on the significant areas related to SA for detecting emotions, developing resources, and utilizing transfer learning. Letarte et al. (2018) explored the modelling of insightful relations between words, in order to understand and enhance predictions and proposed Self-Attention Network (SANet) for text classification. Hussein (2018), Aqlan et al. (2019) did survey son SA focusing on its classification and challenges relevant to their approaches and techniques.
Yue et al. (2019) dealt with SA process and underlying data mining techniques. Dewi et al. (2020) compared classification techniques namely Naïve Bayes and Random Forest, using tokenization and unigram features to build classification model of tweet sentiment. Grljević et al. (2022) for the first time presented a Serbian language corpus manually annotated for opinions in the domain of higher education. The following subsections in detail explain the specific use of SA in different domains.
4.1 Customer Feedback Analysis and Product Reviews
Using sentiment analysis in customer feedback analysis enables a more effective understanding of the opinions and sentiments expressed by customers. Kang and Park (2014) study developed a framework for measuring customer satisfaction of mobile services in Serbian language. Moghaddam (2015) proposed a technique that could automatically extract defects (problem/issue/bug reports) and improvements (modification/upgrade/enhancement requests) from customer feedback and a technique to summarize identified defects and improvements.
Singla et al. (2017) classified sentiments of over 4,000,00 reviews into positive and negative using algorithms such as NaïveBayes, SVM and DT. Zaki and Rodríguez-Díaz (2020) proposed a methodology to identify the labels that could represent the customers’ sentiments, based on a quantitative variable such as overall rating. Adak et al. (2022) reviewed various ML, DL and explainable artificial intelligence models to predict customer sentiments in food delivery services domain. Wu et al. (2022) examined the sentiment information of customer reviews and explore the potential of explored information in enhancing hotel demand forecast. Using LSTM to extract sentiment information from consumer reviews, three sentiment indices, namely, bullish, average and variance index repectively, were constructed and their effectiveness was examined through autoregressive integrated moving average with exogenous variables model. Saroha et al. (2024) suggested that the unification of ML and SA emerges as an effective tool for extraction of emotional traces from unstructured text data.
Yang et al. (2020) introduced a SA model-SLCABG based on sentiment lexicon combining CNN and attention-based BiGRU. Zhao et al. (2021) proposed an optimized ML algorithm called the Local Search Improvised Bat Algorithm based Elman Neural Network (LSIBA-ENN) for the SA of online product reviews.
Kumar et al. (2022) used RNN with GRU to build low-dimensional vector representations of reviews to analyze the sentiment of amazon reviews through paragraph vectors and embedded vectors. Hossain and Rahman (2023) used various SA approaches such as DT, K Neighbours classifier, SVM, logistic regression and random forest classifier TO classify review text into sentiment class to predicted customer review messages. Rasappan et al. (2024) introduced an optimized ML algorithm named Enhanced Golden Jackal Optimizer-based LSTM to perform SA of e-commerce product reviews.
4.2 Social Media
Social media refers to the communication between peoples where they make, share and exchange ideas through various online platform such as Facebook, Twitter, Instagram, YouTube and LinkedIn. SA focusing on social media allows the brands and business to better understand how their products are perceived online and make datadriven decisions to improve products and services. By regularly analysing and acting on this data, business can build a positive brand reputation that resonates with target audience, ultimately driving business success.
SA involving approximately 1000 Facebook post about newscasts was done by Neri et al. (2012), comparing the sentiment for an Italian public broadcasting service against a private company. Maynard et al. (2013) combined opinion mining from text and multimedia (images, videos, etc) on social media focusing on entity and event recognition. Isah et al. (2014) developed a framework for gathering and analysing the views and experiences of users of drug and cosmetic products using ML, text mining and SA. Jurek et al. (2015) presented a LBSA algorithm specifically designed for real time Twitter content analysis. Muhammad et al. (2016) introduced SmartSA, a lexicon-based sentiment classification system for social media genres which integrates strategies to capture contextual polarity from two perspectives: the interaction of terms with their textual neighbourhood (local context) and text genre (global context).
Dhaoui et al. (2017) evaluated and compared the performance of various approaches to automate SA applied to CGC on social media and explored the benefits of combining them. Rathan et al. (2017) higlited the importance of pre-processing of texts in social media in order to obtain important details in various domains thus identifying the trending research areas within social media analysis. Abd El-Jawad et al. (2018) compared the performance of different ML and deep learning algorithms and i a hybrid system using text mining and NN for identifying sentiment classification. Salah et al. (2019), Singh et al. (2020) detailed different approaches for conducting SA and OM and gave a systematic survey on SA and OM techniques. Sharma et al. (2020) discussed the results of different ML techniques based on performance metrics, used for the application of SA in security domains.
4.3 E-Commerce Platforms
E-commerce platforms are platforms where customers trade goods and services via the internet. One major benefit of sentiment analysis in the e-commerce industry is the capability to comprehend customer emotions. This allows businesses to customize product suggestions, ads, and website interfaces, leading to a more interactive and customer-focused setting. By addressing issues and improving positive interactions, e-commerce platforms can greatly increase customer contentment and loyalty. Zheng et al. (2014) proposed a SA model comprising of keyword extraction, polarity assignment technique and graph-based approach for the analysis of mobile handset reviews collected from different electronic commercial sites.
Mittal et al. (2016) analysed online sentiment impact the by analysing a corpus of responses obtained by the consumers and enlisted emoticons, interjections and comments extracted from status updates and posts. Noor et al. (2019) detailed SA on women’s e-commerce reviews from Amazon using Weka. The study compared classifiers namely J48, Naïve Bayes, JRip, and SMO for SA based on categories and AdaBoost. Yang et al. (2020) proposed a SA model-SLCABG based on the sentiment lexicon, CNN and attention based BiGRU.
Marong et al. (2020) overviewed SA and its techniques in e-commerce sector about the consumers’ opinions of their goods and services. Baishya et al. (2021) applied the bag of words model and glove embedding matrix to focus on fake reviews. El-Ansari et al. (2023) detailed and evaluated the components and techniques employed for handling user queries and effectiveness of system, that implemented a concept of customer service chatbot. Kyaw et al. (2023) observed the applications of SA in E-commerce systems as a comprehensive study and pointed out the role of discovering business intelligence through SA for smart digital marketing in E-commerce platforms Hajek et al. (2023) used ABSA for fake review detection.
4.4 Political Reviews and Analysis
SA is an integral part of any political campaign as it provides insights into voters’ moods and opinion. Social media platform, such as Twitter consistently generates corpus text containing political insights, is usually mined to analyse the people’s opinion and predict the future trends and even the results of the elections. Tumasjan et al. (2010) conducted the content analysis of more than 100.000 tweets containing the reference to either a political party or a politician and concluded that twitter is used extensively for political deliberation. Bakliwal et al. (2013) performed a three class sentiment classification experiments on a collection of 2624 tweets posted during the run-up to the Irish General elections in 2011 and the highest accuracy achieved was 61.6% by supervised learning.
Nandi et al. (2016) did the SA of tweets, by combining the lexical dictionary-based approach and SVM learning classifier, to conclude the public opinions towards the political parties and achieved an accuracy of 93%. Sharma et al. (2016) made use of both supervised and unsupervised approaches to perform text mining on 42,235 tweets in Hindi language during the general state elections in 2016 and SVM predicted a 78.4% chance that the Bhartiya Janta Party (BJP) would win more elections and it turned out to be true.
The work presented by Ramteke et al. (2016) analysed Twitter sentiment to determine public views before, during and after elections respectively and the result reveaedl that the elections outcomes align with the sentiment expressed on social media in most of the cases and the sentiment classifier showed the accuracy of 94.58% with the precision of 93.19%. Sandoval-Almazan and Valle-Cruz (2018) analysed the data collected from around 4000 posts on Facebook about the local government campaign in the central State of Mexico and revealed that the voters’ perception of candidates was bad for the winner political party. Roy et al. (2019) summarized the data set of tweets related to the 14th Gujrat Legislative Assembly election to predict the chances of winner party by utilizing public’s opinion and presumed that only English language is not enough for the accurate sentiment analysis as most of the common people express their opinions in native languages.
Onyenwe et al. (2022) investigated the impact of political party and control over its candidate and vice versa on winning an election and deduced from the experiment’s results that the acceptance of the candidate or the party adds to the win in the election. The method applied by Rodríguez-Ibáñez et al. (2021) to analyse the statistical and temporal dynamics of SA on political campaigns and found measurable variations in sentiment behavior and polarity across the political parties and their leaders throughout the election period. Chauhan et al. (2021) reviewed the studies that tried to infer the political opinion of public using social media platforms and tried to edify the contribution of the researchers to predict election results through social media content.
5 Conclusion, Challenges and Future Scope
This study is a systematic review of works related to SA and NLP tasks in a chronological order. Applications of SA and SA related techniques specially in business and politics has also been discussed. Finding suggest that though the early models of SA were lexicon based, later models were developed using neural networks, RNN and CNN’s. Recent trends show shifting of interest towards machine leaning and hybrid models in developing SA related models. SA models are actively being in developed in various languages especially Arabic and are not just limited to English. Sarcasm, multi-lingual texts still are persistent challenges in the field of SA. As emojis and gif’s have become an integral part of posts especially in social media, some authors try to incorporate them in their models in order to properly identify and analyse the sentiments. SA models are going to be comparatively smarter and more efficient in the near future due to a boom in ML and AI sector. Which could be seen as a necessity due to the introduction of big data and big data analytics in social media and services sector.
Deep learning has established itself as the cornerstone of modern sentiment analysis by improving classification accuracy and contextual comprehension. The integration of Transformer-based models, attention mechanisms, and multimodal learning continues to expand the potential of sentiment detection across platforms. Future advancements are expected to focus on Explainable AI (XAI) for transparent predictions, real-time multimodal sentiment analysis for social media monitoring, and ethically aligned models that mitigate algorithmic bias and preserve data privacy.
Competing Interest Declaration
The authors of this manuscript have no competing interest.
Data Declaration
Authors do not have any data to declare.
References
Abd El-Jawad, M. H., Hodhod, R., and Omar, Y. M. (2018, December). Sentiment analysis of social media networks using machine learning. In 2018 14th international computer engineering conference (ICENCO) (pp. 174–176). IEEE.
Abdou, A. L. N. N., and Tagne, E. F. (2021, December). A Sentiment Analysis Approach for Abusive Content Detection using Improved Dataset. In 2021 International Conference on Computational Science and Computational Intelligence (CSCI) (pp. 1415–1420). IEEE.
Abdulla, N. A., Ahmed, N. A., Shehab, M. A., and Al-Ayyoub, M. (2013, December). Arabic sentiment analysis: Lexicon-based and corpus-based. In 2013 IEEE Jordan conference on applied electrical engineering and computing technologies (AEECT) (pp. 1–6). IEEE.
Adak, A., Pradhan, B., and Shukla, N. (2022). Sentiment analysis of customer reviews of food delivery services using deep learning and explainable artificial intelligence: Systematic review. Foods, 11(10), 1500.
Agarwal, B., and Mittal, N. (2013, June). Sentiment classification using rough set based hybrid feature selection. In Proceedings of the 4th workshop on computational approaches to Subjectivity, sentiment and social media analysis (pp. 115–119).
Agarwal, B., Mittal, N., Bansal, P., and Garg, S. (2015). Sentiment analysis using common-sense and context information. Computational intelligence and neuroscience, 2015, 30–30.
Al Amrani, Y., Lazaar, M., and El Kadiri, K. E. (2018). A novel hybrid classification approach for sentiment analysis of text document. Int. J. Electr. Comput. Eng, 8(6), 4554–4567.
AlBadani, Barakat, Shi, Ronghua and Dong, Jian. (2022). A Novel Machine Learning Approach for Sentiment Analysis on Twitter Incorporating the Universal Language Model Fine-Tuning and SVM. Applied System Innovation. 5. 13. DOI: 10.3390/asi5010013.
Alharbi, J. R., and Alhalabi, W. S. (2020). Hybrid approach for sentiment analysis of twitter posts using a dictionary-based approach and fuzzy logic methods: Study case on cloud service providers. International Journal on Semantic Web and Information Systems (IJSWIS), 16(1), 116–145.
Alqaryouti, O., Siyam, N., Abdel Monem, A., and Shaalan, K. (2024). Aspect-based sentiment analysis using smart government review data. Applied Computing and Informatics, 20(1/2), 142–161.
Alshuwaier, F., Areshey, A., and Poon, J. (2022). Applications and enhancement of document-based sentiment analysis in deep learning methods: Systematic literature review. Intelligent Systems with Applications, 15, 200090.
Altaher, A. (2017). Hybrid approach for sentiment analysis of Arabic tweets based on deep learning model and features weighting. Int. J. Adv. Appl. Sci, 4(8), 43–49.
Appel, O., Chiclana, F., Carter, J., and Fujita, H. (2016). A hybrid approach to the sentiment analysis problem at the sentence level. Knowledge-Based Systems, 108, 110–124.
Appel, O., Chiclana, F., Carter, J., and Fujita, H. (2018). Successes and challenges in developing a hybrid approach to sentiment analysis. Applied Intelligence, 48, 1176–1188.
Aqlan, A. A. Q., Manjula, B., and Lakshman Naik, R. (2019). A study of sentiment analysis: concepts, techniques, and challenges. In Proceedings of International Conference on Computational Intelligence and Data Engineering: Proceedings of ICCIDE 2018 (pp. 147–162). Springer Singapore.
Babu, N. V., and Kanaga, E. G. M. (2022). Sentiment analysis in social media data for depression detection using artificial intelligence: a review. SN computer science, 3(1),
Baishya, D., Deka, J. J., Dey, G., and Singh, P. K. (2021). SAFER: sentiment analysis-based fake review detection in e-commerce using deep learning. SN Computer Science
Bakliwal, A., Foster, J., van der Puil, J., O’Brien, R., Tounsi, L., and Hughes, M. (2013, June). Sentiment analysis of political tweets: Towards an accurate classifier. Association for Computational Linguistics.
Basiri, M. E., and Kabiri, A. (2017, October). Translation is not enough: comparing lexicon-based methods for sentiment analysis in Persian. In 2017 international symposium on computer science and software engineering conference (CSSE) (pp. 36–41). IEEE
Begg, R., and Kamruzzaman, J. (2005). A machine learning approach for automated recognition of movement patterns using basic, kinetic and kinematic gait data. Journal of biomechanics, 38(3), 401–408.
Beigi, G., Hu, X., Maciejewski, R., and Liu, H. (2016). An overview of sentiment analysis in social media and its applications in disaster relief. Sentiment analysis and ontology engineering: An environment of computational intelligence, 313–340.
Cao Q, Duan W, Gan Q (2011) Exploring determinants of voting for the “helpfulness” of online user reviews: a text mining approach. Decis Support Syst 50(2):511–521
Catelli, R., Pelosi, S., Comito, C., Pizzuti, C., and Esposito, M. (2023). Lexicon-based sentiment analysis to detect opinions and attitude towards COVID-19 vaccines on Twitter in Italy. Computers in Biology and Medicine, 158, 106876.
Chathuranga, P. D. T., Lorensuhewa, S. A. S., and Kalyani, M. A. L. (2019, September). Sinhala sentiment analysis using corpus based sentiment lexicon. In 2019 19th international conference on advances in ICT for emerging regions (ICTer) (Vol. 250, pp. 1–7). IEEE.
Chau, M., and Chen, H. (2008). A machine learning approach to web page filtering using content and structure analysis. Decision Support Systems, 44(2), 482–494.
Chauhan, G. S., Nahta, R., Meena, Y. K., and Gopalani, D. (2023). Aspect based sentiment analysis using deep learning approaches: A survey. Computer Science Review, 49, 100576.
Chauhan, P., Sharma, N., and Sikka, G. (2021). The emergence of social media data and sentiment analysis in election prediction. Journal of Ambient Intelligence and Humanized Computing, 12, 2601–2627.
Che, W., Zhao, Y., Guo, H., Su, Z., and Liu, T. (2015). Sentence compression for aspect-based sentiment analysis. IEEE/ACM Transactions on audio, speech, and language processing, 23(12), 2111–2124.
Ciftci, B., and Apaydin, M. S. (2018, September). A deep learning approach to sentiment analysis in Turkish. In 2018 international conference on artificial intelligence and data processing (IDAP) (pp. 1–5). IEEE.
Dave, K., Lawrence, S., and Pennock, D. M. (2003, May). Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In Proceedings of the 12th international conference on World Wide Web (pp. 519–528).
De Arruda, H. F., Marinho, V. Q., Costa, L. D. F., and Amancio, D. R. (2019). Paragraph-based representation of texts: A complex networks approach. Information Processing & Management, 56(3), 479–494.
De Clercq, O., Lefever, E., Jacobs, G., Carpels, T., and Hoste, V. (2017, September). Towards an integrated pipeline for aspect-based sentiment analysis in various domains. In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (pp. 136–142).
Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. (2019, June). Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) (pp. 4171–4186).
Dewi, T. B. T., Indrawan, N. A., Budi, I., Santoso, A. B., and Putra, P. K. (2020, September). Community understanding of the importance of social distancing using sentiment analysis in Twitter. In 2020 3rd International Conference on Computer and Informatics Engineering (IC2IE) (pp. 336–341). IEEE.
Dhaoui, C., Webster, C. M., and Tan, L. P. (2017). Social media sentiment analysis: lexicon versus machine learning. Journal of Consumer Marketing, 34(6), 480–488.
El-Ansari, A., and Beni-Hssane, A. (2023). Sentiment analysis for personalized chatbots in e-commerce applications. Wireless Personal Communications, 129(3), 1623–1644.
Ferguson, P., O’Hare, N., Davy, M., Bermingham, A., Sheridan, P., Gurrin, C., and Smeaton, A. F. (2009). Exploring the use of paragraph-level annotations for sentiment analysis of financial blogs.
Ghorbani, M., Bahaghighat, M., Xin, Q., and Özen, F. (2020). ConvLSTMConv network: a deep learning approach for sentiment analysis in cloud computing. Journal of Cloud Computing, 9(1), 16.
Gonçalves, P., Araújo, M., Benevenuto, F., and Cha, M. (2013, October). Comparing and Combining sentiment analysis methods. In Proceedings of the first ACM conference on online social networks (pp. 27–38).
Govindarajan, M. (2014). Sentiment classification of movie reviews using hybrid method. International Journal of Advances in Science Engineering and Technology, 1(3), 73–77.
Grljević, O., Bošnjak, Z., and Kovačević, A. (2022). Opinion mining in higher education: a corpus-based approach. Enterprise Information Systems, 16(5), 1773542.
Hajek, P., Hikkerova, L., and Sahut, J. M. (2023). Fake review detection in e-Commerce platforms using aspect-based sentiment analysis. Journal of Business Research, 167, 114143.
Hassan, A., and Mahmood, A. (2017, April). Deep learning approach for sentiment analysis of short texts. In 2017 3rd international conference on control, automation and robotics (ICCAR) (pp. 705–710). IEEE.
Hausler, J., Ruscheinsky, J. and Lang, M. (2018) ’News-based sentiment analysis in real estate: a machine learning approach’, Journal of Property Research, 35(4), pp. 344–371. DOI: 10.1080/09599916.2018.1551923.
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735–1780.
Hossain, M. S., and Rahman, M. F. (2023). Customer sentiment analysis and prediction of insurance products’ reviews using machine learning approaches. FIIB Business Review, 12(4), 386–402.
Hovy, E. H. (2015). What are sentiment, affect, and emotion? Applying the methodology of Michael Zock to sentiment analysis. Language production, cognition, and the Lexicon, 13–24.
Hussein, D. M. E. D. M. (2018). A survey on sentiment analysis challenges. Journal of King Saud University-Engineering Sciences, 30(4), 330–338.
Iqbal, F., Hashmi, J. M., Fung, B. C., Batool, R., Khattak, A. M., Aleem, S., and Hung, P. C. (2019). A hybrid framework for sentiment analysis using genetic algorithm based feature reduction. IEEE Access, 7, 14637–14652.
Isah, H., Trundle, P., and Neagu, D. (2014, September). Social media analysis for product safety using text mining and sentiment analysis. In 2014 14th UK workshop on computational intelligence (UKCI) (pp. 1–7). IEEE.
Jagdale, R. S., Shirsat, V. S., and Deshmukh, S. N. (2019). Sentiment analysis on product reviews using machine learning techniques. In Cognitive Informatics and Soft.
Jurek, A., Mulvenna, M. D., and Bi, Y. (2015). Improved lexicon-based sentiment analysis for social media analytics. Security Informatics, 4, 1–13.
Kabir, M., Kabir, M. M. J., Xu, S., and Badhon, B. (2021). An empirical research on sentiment analysis using machine learning approaches. International Journal of Computers and Applications, 43(10), 1011–1019.
Kanayama, H., and Nasukawa, T. (2006, July). Fully automatic lexicon expansion for domain-oriented sentiment analysis. In Proceedings of the 2006 conference on empirical methods in natural language processing (pp. 355–363).
Kang, D., and Park, Y. (2014). Based measurement of customer satisfaction in mobile service: Sentiment analysis and VIKOR approach. Expert Systems with Applications, 41(4), 1041–1050.
Karlgren, J., and Cutting, D. (1994). Recognizing text genres with simple metrics using discriminant analysis. arXiv preprint cmp-Ig/941 0008.
Kaur, G., and Sharma, A. (2023). A deep learning-based model using hybrid feature extraction approach for consumer sentiment analysis. Journal of big data, 10(1), 5.
Kaur, J., and Sidhu, B. K. (2018, June). Sentiment analysis based on deep learning approaches. In 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS) (pp. 1496–1500). IEEE.
Ke, W., and Chan, K. H. (2021). A multilayer CARU framework to obtain probability distribution for paragraph-based sentiment analysis. Applied Sciences, 11(23), 11344.
Kessler, B., Nunberg, G., and Schütze, H. (1997). Automatic detection of text genre. arXiv preprint cmplg/9707002.
Khan, A., Baharudin, B., and Khan, K. (2010, December). Sentence based sentiment classification from online customer reviews. In Proceedings of the 8th International Conference on Frontiers of Information Technology (pp. 1–6).
Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882.
Kumar, A., Setia, S., Singh, A., Abraham, T., and Shakya, Y. (2022). Sentimental Analysis using Product Review Data. Telecom Business Review, 15(1), 11.
Kumar, P., and Jaiswal, U. C. (2016). A comparative study on sentiment analysis and opinion mining. Int J Eng Technol, 8(2), 938–943.
Kyaw, K. S., Tepsongkroh, P., Thongkamkaew, C., and Sasha, F. (2023). Business intelligent framework using sentiment analysis for smart digital marketing in the E-commerce era. Asia Social Issues, 16(3), e252965–e252965.
Lagrari, F. E., and Elkettani, Y. (2021). Traditional and deep learning approaches for sentiment analysis: A survey. Advances in Science, Technology and Engineering Systems Journal, 6(4), 1–7.
Letarte, G., Paradis, F., Giguère, P., and Laviolette, F. (2018, November). Importance of self-attention for sentiment analysis. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP (pp. 267–275).
Li, S. (2013). Sentiment classification using subjective and objective views. International Journal of Computer Applications, 80(7).
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … and Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Lubis, A. R., Nasution, M. K., Sitompul, O. S., and Zamzami, E. M. (2020, July). A framework of utilizing big data of social media to find out the habits of users using keyword. In Proceedings of the 8th International Conference on Computer and Communications Management (pp. 140–144).
Ma, Y., Peng, H., Khan, T., Cambria, E., and Hussain, A. (2018). Sentic LSTM: a hybrid network for targeted aspect-based sentiment analysis. Cognitive Computation, 10, 639–650.
Maite Taboada, Julian Brooke, Milan Tofiloski, Kimberly Voll, Manfred Stede; Lexicon-Based Methods for Sentiment Analysis. Computational Linguistics 2011; 37(2): 267–307.
Malandrakis, N., Kazemzadeh, A., Potamianos, A., and Narayanan, S. (2013, June). SAIL: A hybrid approach to sentiment analysis. In Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013) (pp. 438–442).
Marong, M., Batcha, N. K., and Mafas, R. (2020). Sentiment Analysis in E-Commerce: A Review on The Techniques and Algorithms. Journal of Applied Technology and Innovation (e-ISSN: 2600–7304), 4(1), 6.
Maynard, D., Dupplaw, D., and Hare, J. (2013). Multimodal sentiment analysis of social media.
Melville, P., Gryc, W., and Lawrence, R. D. (2009, June). Sentiment analysis of blogs by combining lexical knowledge with text classification. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1275–1284).
Mendon, S., Dutta, P., Behl, A., and Lessmann, S. (2021). A hybrid approach of machine learning and lexicons to sentiment analysis: Enhanced insights from twitter data of natural disasters. Information Systems Frontiers, 23(5), 1145–1168.
Mittal, N., Agarwal, B., Agarwal, S., Agarwal, S., and Gupta, P. (2013). A hybrid approach for twitter sentiment analysis. In 10th international conference on NLP (ICON-2013) (pp. 116–120).
Mittal, S., Goel, A., and Jain, R. (2016, March). Sentiment analysis of E-commerce and social networking sites. In 2016 3rd International Conference on Computing for Sustainable Global Development (INDIA Com) (pp. 2300–2305). IEEE.
Moghaddam, S. (2015). Beyond sentiment analysis: mining defects and improvements from customer feedback. In Advances in Information Retrieval: 37th European Conference on IR Research, ECIR 2015, Vienna, Austria, March 29–April 2, 2015. Proceedings 37 (pp. 400–410). Springer International Publishing.
Montoyo, A., Martínez-Barco, P., and Balahur, A. (2012). Subjectivity and sentiment analysis: An overview of the current state of the area and envisaged developments. Decision Support Systems, 53(4), 675–679.
Moreno-Ortiz, A., and Fernández-Cruz, J. (2015). Identifying polarity in financial texts for sentiment analysis: a corpus-based approach. Procedia-Social and Behavioral Sciences, 198, 330–338.
Morinaga, S., Yamanishi, K., Tateishi, K., and Fukushima, T. (2002, July). Mining product reputations on the web. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 341–349).
Muhammad, A., Wiratunga, N., and Lothian, R. (2016). Contextual sentiment analysis for social media genres. Knowledge-based systems, 108, 92–101.
Mukwazvure, A., and Supreethi, K. P. (2015, September). A hybrid approach to sentiment analysis of news comments. In 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO)(Trends and Future Directions) (pp. 1–6). IEEE.
Mullen, T., and Collier, N. (2004, July). Sentiment analysis using SVM with diverse information sources. In Proceedings of the 2004 conference on empirical methods in NLP (pp. 412–418).
Müller, K. R., Tangermann, M., Dornhege, G., Krauledat, M., Curio, G., and Blankertz, B. (2008). Machine learning for real-time single-trial EEG-analysis: from brain-computer interfacing to mental state monitoring. Journal of neuroscience methods, 167(1), 82–90.
Nadeau, D., Sabourin, C., De Koninck, J., Matwin, S., and Turney, P. D. (2006, July). Automatic dream sentiment analysis. In Proceedings of the Workshop on Computational Aesthetics at the Twenty-First National Conference on Artificial Intelligence.
Nandi, V., and Agrawal, S. (2016). Political sentiment analysis using hybrid approach. International Research Journal of Engineering and Technology, 3(5), 1621–1627.
Nanli, Z., Ping, Z., Weiguo, L. I., and Meng, C. (2012, November). Sentiment analysis: A Literature review. In 2012 International Symposium on Management of Technology (ISMOT) (pp. 572–576). IEEE.
Nasukawa, T., and Yi, J. (2003, October). Sentiment analysis: Capturing favorability using NLP. In Proceedings of the 2nd international conference on Knowledge capture (pp. 70–77).
Nazir, A., Rao, Y., Wu, L., and Sun, L. (2020). Issues and challenges of aspect-based sentiment analysis: A comprehensive survey. IEEE Transactions on Affective Computing, 13(2), 845–863.
Neethu, M. S., and Rajasree, R. (2013, July). Sentiment analysis in twitter using machine learning techniques. In 2013 fourth international conference on computing, communications and networking technologies (ICCCNT) (pp. 1–5). IEEE.
Neri, F., Aliprandi, C., Capeci, F., and Cuadros, M. (2012, August). Sentiment analysis on social media. In 2012 IEEE/ACM international conference on advances in social networks analysis and mining (pp. 919–926). IEEE.
Noor, A., and Islam, M. (2019, July). Sentiment Analysis for Women’s E-commerce Reviews using Machine Learning Algorithms. In 2019 10th International conference on computing, communication and networking technologies (ICCCNT) (pp. 1–6).
Noor, A., and Islam, M. (2019, July). Sentiment Analysis for Women’s E-commerce Reviews using Machine Learning Algorithms. In 2019 10th International conference on computing, communication and networking technologies (ICCCNT) (pp. 1–6).
O’Hare, N., Davy, M., Bermingham, A., Ferguson, P., Sheridan, P., Gurrin, C., and Smeaton, A. F. (2009, November). Topic-dependent sentiment analysis of financial blogs. In Proceedings of the 1st international CIKM workshop on Topic-sentiment analysis for mass opinion (pp. 9–16).
Onyenwe, I., Nwagbo, S., Mbeledogu, N., and Onyedinma, E. (2020). The impact of political party/candidate on the election results from a sentiment analysis perspective using# AnambraDecides2017 tweets. Social Network Analysis and Mining, 10, 1–17.
P.D. Turney, Thumbs up or thumbs down?: Semantic orientation applied to unsupervised classification of reviews, in: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, 2002, pp. 417–424.
Pandarachalil, R., Sendhilkumar, S., Mahalakshmi, G.S.: Twitter sentiment analysis for largescale data: an unsupervised approach. Cogn. Comput. 7(2), 254–262 (2015)
Pang, B., and Lee, L. (2008). Opinion mining and sentiment analysis. Foundations and Trends® in information retrieval, 2(1–2), 1–135.
Pang, B., Lee, L., and Vaithyanathan, S. (2002). Thumbs up? Sentiment classification using machine learning techniques. arXiv preprint cs/0205070.
Park S, Kim Y (2016) Building thesaurus lexicon using dictionary-based approach for sentiment classifica tion. In: 2016 IEEE 14th international conference on software engineering research, management and applications (SERA), pp. 39–44.
Pavlopoulos, J., and Androutsopoulos, I. (2014, April). Multi-granular aspect aggregation in aspectbased sentiment analysis. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics (pp. 78–87).
Pawar, A. B., Jawale, M. A., and Kyatanavar, D. N. (2016). Fundamentals of sentiment analysis: concepts and methodology. Sentiment analysis and ontology engineering: An environment of computational intelligence, 25–48.
Phan, M. H., and Ogunbona, P. O. (2020, July). Modelling context and syntactical features for aspectbased sentiment analysis. In Proceedings of the 58th annual meeting of the association for computational linguistics (pp. 3211–3220).
Qi, B., and Costin, A. M. (2019, June). Investigation of the influence of Twitter user habits on sentiment of their opinions towards transportation services. In ASCE International Conference on Computing in Civil Engineering 2019 (pp. 314–321). Reston, VA: American Society of Civil Engineers.
Ramirez-Alcocer, U. M., Tello-Leal, E., Hernandez-Resendiz, J. D., and Romero, G. (2024). A Hybrid CNN-LSTM Approach for Sentiment Analysis. In Congress on Intelligent Systems (pp. 425–437). Springer, Singapore.
Ramteke, J., Shah, S., Godhia, D., and Shaikh, A. (2016, August). Election result prediction using Twitter sentiment analysis. In 2016 international conference on inventive computation technologies (ICICT) (Vol. 1, pp. 1–5). IEEE.
Rani, P., Liu, C., Sarkar, N., and Vanman, E. (2006). An empirical study of machine learning techniques for affect recognition in human-robot interaction. Pattern Analysis and Applications, 9, 58–69.
Rasappan, P., Premkumar, M., Sinha, G., and Chandrasekaran, K. (2024). Transforming sentiment analysis for e-commerce product reviews: Hybrid deep learning model with an innovative term weighting and feature selection. Information Processing & Management, 61(3), 103654.
Rathan, M., Hulipalled, V. R., Murugeshwari, P., and Sushmitha, H. M. (2017, August). Every post matters: a survey on applications of sentiment analysis in social media. In 2017 International Conference On Smart Technologies For Smart Nation (SmartTechCon) (pp. 709–714). IEEE.
Rice, D. R., and Zorn, C. (2021). Corpus-based dictionaries for sentiment analysis of specialized vocabularies. Political Science Research and Methods, 9(1), 20–35.
Rodríguez-Ibáñez, M., Gimeno-Blanes, F. J., Cuenca-Jiménez, P. M., Soguero-Ruiz, C., and Rojo-Álvarez, J. L. (2021). Sentiment analysis of political tweets from the 2019 Spanish elections. IEEE Access, 9, 101847–101862.
Ruder, S., Ghaffari, P., and Breslin, J. G. (2016). A hierarchical model of reviews for aspect-based sentiment analysis. arXiv preprint arXiv:1609.02745.
Sai Nikhita, N, Hyndavi, V, and Trupthi, M (2020). Detection of Inappropriate Anonymous Comments Using NLP and Sentiment Analysis. In Advances in Decision Sciences, Image Processing, Security and Computer Vision: International Conference on Emerging Trends in Engineering (ICETE), Vol. 1 (pp. 131–138). Springer International Publishing.
Salah, Z., Al-Ghuwairi, A. R. F., Baarah, A., Aloqaily, A., Qadoumi, B. A., Alhayek, M., and Alhijawi, B. (2019). A systematic review on opinion mining and sentiment analysis in social media. International Journal of Business Information Systems, 31(4), 530–554.
Sallam, R. M., Hussein, M., and Mousa, H. M. (2022). Improving collaborative filtering using lexiconbased sentiment analysis. International Journal of Electrical and Computer Engineering, 12(2), 1744.
Sandoval-Almazan, R., and Valle-Cruz, D. (2018, May). Facebook impact and sentiment analysis on political campaigns. In Proceedings of the 19th annual international conference on digital government research: governance in the data age (pp. 1–7).
Saroha, K., Sehrawat, M., and Jain, V. (2024). Machine Learning and Sentiment Analysis for Analyzing Customer Feedback: A Review. Big Data Analytics Techniques for Market Intelligence, 411–440.
Sharma, P., and Moh, T. S. (2016, December). Prediction of Indian election using sentiment analysis on Hindi Twitter. In 2016 IEEE international conference on big data (big data) (pp. 1966–1971). IEEE.
Sharma, S., and Jain, A. (2020). Role of sentiment analysis in social media security and analytics. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 10(5), e1366.
Singh, N. K., Tomar, D. S., and Sangaiah, A. K. (2020). Sentiment analysis: a review and comparative analysis over social media. Journal of Ambient Intelligence and Humanized Computing, 11(1), 97–117.
Singla, Z., Randhawa, S., and Jain, S. (2017, June). Sentiment analysis of customer product reviews using machine learning. In 2017 international conference on intelligent computing and control (I2C2) (pp. 1–5). IEEE.
Sunitha, D., Patra, R. K., Babu, N. V., Suresh, A., and Gupta, S. C. (2022). Twitter sentiment analysis using ensemble based deep learning model towards COVID-19 in India and European countries. Pattern Recognition Letters, 158, 164–170.
Taj, S., Shaikh, B. B., and Meghji, A. F. (2019, January). Sentiment analysis of news articles: a lexicon based approach. In 2019 2nd international conference on computing, mathematics and engineering technologies (iCoMET) (pp. 1–5). IEEE.
Tan, K. L., Lee, C. P., Lim, K. M., and Anbananthen, K. S. M. (2022). Sentiment analysis with ensemble hybrid deep learning model. IEEE Access, 10, 103694–103704.
Tang, D. (2015, February). Sentiment-specific representation learning for document-level sentiment analysis. In Proceedings of the eighth ACM international conference on web search and data mining (pp. 447452).
Tang, D., Qin, B., and Liu, T. (2015). Deep learning for sentiment analysis: successful approaches and future challenges. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 5(6), 292–303.
Trilla, A., and Alias, F. (2012). Sentence-based sentiment analysis for expressive text-to-speech. IEEE transactions on audio, speech, and language processing, 21(2), 223–233.
Tumasjan, A., Sprenger, T., Sandner, P., and Welpe, I. (2010, May). Predicting elections with twitter: What 140 characters reveal about political sentiment. In Proceedings of the international AAAI conference on web and social media (Vol. 4, No. 1, pp. 178–185).
Turney, P. D. (2002). Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. arXiv preprint cs/0212032.
Turney, P. D., and Littman, M. L. (2003). Measuring praise and criticism: Inference of semantic orientation from association. Acm Transactions on Information Systems (tois), 21(4), 315–346.
Rohani, V. A., and Shayaa, S. (2015, August). Utilizing machine learning in Sentiment Analysis: SentiRobo approach. In 2015 International Symposium on Technology Management and Emerging Technologies (ISTMET) (pp. 263–267). IEEE.
Varghese, R., and Jayasree, M. (2013, August). Aspect based sentiment analysis using support vector machine classifier. In 2013 international conference on advances in computing, communications and informatics (ICACCI) (pp. 1581–1586). IEEE.
Vinodhini, G., and Chandrasekaran, R. M. (2012). Sentiment analysis and opinion mining: a Survey. International Journal, 2(6), 282–292.
Wang, C. J., Tsai, M. F., Liu, T., and Chang, C. T. (2013, October). Financial sentiment analysis for risk prediction. In Proceedings of the Sixth International Joint Conference on NLP (pp. 802–808).
Wang, J., Xu, B., and Zu, Y. (2021, July). Deep learning for aspect-based sentiment analysis. In 2021 international conference on machine learning and intelligent systems engineering (MLISE) (pp. 267–271). IEEE.
Whitelaw, C., Garg, N., and Argamon, S. (2005, October). Using appraisal groups for sentiment analysis. In Proceedings of the 14th ACM international conference on Information and knowledge management (pp. 625–631).
Wiebe, J. (2000). Learning subjective adjectives from corpora. Aaai/iaai, 20(0), 0.
Wilson, T., Wiebe, J., and Hoffmann, P. (2005, October). Recognizing contextual polarity in phraselevel sentiment analysis. In Proceedings of human language technology conference and conference on empirical methods in NLP (pp. 347–354).
Wilson, T., Wiebe, J., and Hoffmann, P. (2009). Recognizing contextual polarity: An exploration of features for phrase-level sentiment analysis. Computational linguistics, 35(3), 399–433.
Wu, D. C., Zhong, S., Qiu, R. T., and Wu, J. (2022). Are customer reviews just reviews? Hotel forecasting using sentiment analysis. Tourism Economics, 28(3), 795–816.
Xu, H., Liu, B., Shu, L., and Yu, P. S. (2019). BERT post-training for review reading comprehension and aspect-based sentiment analysis. arXiv preprint arXiv:1904.02232.
Yang, L., Li, Y., Wang, J., and Sherratt, R. S. (2020). Sentiment analysis for E-commerce product reviews in Chinese based on sentiment lexicon and deep learning. IEEE access, 8, 23522–23530, IEEE.
Yu, J., Chen, K., and Xia, R. (2022). Hierarchical interactive multimodal transformer for aspect-based multimodal sentiment analysis. IEEE Transactions on Affective Computing, 14(3), 1966–1978.
Yue, L., Chen, W., Li, X., Zuo, W., and Yin, M. (2019). A survey of sentiment analysis in social media. Knowledge and Information Systems, 60, 617–663
Zaki Ahmed, A., and Rodríguez-Díaz, M. (2020). Significant labels in sentiment analysis of online customer reviews of airlines. Sustainability, 12(20), 8683.
Zhang, W., Li, X., Deng, Y., Bing, L., and Lam, W. (2022). A survey on aspect-based sentiment analysis: Tasks, methods, and challenges. IEEE Transactions on Knowledge and Data Engineering.
Zhao, G., Luo, Y., Chen, Q., and Qian, X. (2023). Aspect-based sentiment analysis via multitask learning for online reviews. Knowledge-Based Systems, 264, 110326.
Zhao, H., Liu, Z., Yao, X., and Yang, Q. (2021). A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach. Information Processing & Management, 58(5), 102656.
Zheng, L., Jin, P., Zhao, J., and Yue, L. (2014). Multi-dimensional sentiment analysis for large-scale Ecommerce reviews. In Database and Expert Systems Applications: 25th International Conference, DEXA 2014, Munich, Germany, September 1–4, 2014. Proceedings, Part II 25 (pp. 449–463). Springer International Publishing.
Biographies

Muskan Mahato completed her B.Sc. (Honours) in Mathematics from Graphic Era University, Dehradun, and is currently pursuing her M.Sc. in Mathematics from VSKC College, Dakpathar. Her research interests include sentiment analysis and data analysis.

Anjali is a graduate in Mathematics from Graphic Era Hill University. Along with her academic training in analytical and problem-solving methods, she has professional experience in the fields of marketing and data analysis, where she applies quantitative thinking to understand patterns, performance, and decision-making.

Archana Negi completed her B.Sc. (Honours) in Mathematics from Graphic Era University, Dehradun. Her research interests include sentiment analysis and data analysis and currently, she is preparing for competitive government examinations.

Priya Bisht is a graduate in Mathematics from Graphic Era Hill University. Her research interests include sentiment analysis and data analysis, and she is currently preparing for competitive government examinations. Alongside she is dedicated to research on areas related to AI and ML Models.

Makrand Dhyani is currently associated with Graphic Era Hill University, Dehradun in Department of Mathematics as an Assistant Professor of Mathematics. He has been in acadmiea professionaly for over 3 years. His research areas include fuzzy set theory, fuzzy logic, sentiment and personality analysis.

Raj Kishor Bisht is a Professor in the School of Computing at Graphic Era Hill University, Dehradun. His research areas include data analytics, machine learning, and natural language processing, with a particular focus on the logical and mathematical foundations of computation. His ongoing work explores the integration of AI with data-driven decision-making and the development of interpretable and robust computational models.

Chandan Singh Ujarari received the B.Sc. and M.Sc. degree from Kumaun University, Nainital, India in 2006 and 2008 respectively, and the Ph.D. degree major in Mathematics and minor in Computer science from G. B. Pant University of Agriculture and Technology, Pantnagar, India, in 2016. He is currently working as an Assistant Professor in the Department of Mathematics, Graphic Era Hill University, Dehradun in India.
Journal of Graphic Era University, Vol. 14_2, 347–388
doi: 10.13052/jgeu0975-1416.1422
© 2026 River Publishers