Radial Orthogonal Median LBP (ROM-LBP): A Discriminant Local Descriptor in Light Variations for Face Recognition
Shekhar Karanwal* and Manoj Diwakar
Department of Computer Science & Engineering, Graphic Era Deemed to be University, Dehradun, Uttarakhand, India
E-mail: shekhar.karanwal@gmail.com; manoj.diwakar@gmail.com
*Corresponding Author
Received 16 March 2022; Accepted 11 June 2022; Publication 23 July 2022
Abstract
LBP and majority of its variants performs extremely well in front of moderate light variations. But when light variations becomes severe then performance of LBP and its variants is not satisfactory. Therefore there is a need of the more promising and impressive descriptor which performs well in harsh light variations. To complement these LBP based descriptors the proposed work launches the novel descriptor for Face Recognition (FR) in harsh lightning variations. This proposed descriptor is called as Radial Orthogonal Median LBP (ROM-LBP). The main demerit of these LBP based descriptors is that they all consider the uniform coordination between the neighbors and center pixel. Which mean raw pixel intensity is used for the comparison with the center pixel. The proposed work eliminates this problem in the introduced descriptor ROM-LBP, by replacing the raw pixels intensity with the median of the radial points in each orthogonal position of the two separate groups. The generated median is then used for comparison with the center pixel. The respective codes obtained from both the groups are concatenated to form the ROM-LBP size. As region feature extraction is done therefore ROM-LBP develops the large feature size. To make more effective descriptor, the services of FLDA is used and then classification was conducted by SVMs. Experiments conducted on EYB and YB datasets demonstrates the ability of the proposed ROM-LBP against various LBP and non-LBP based descriptors.
Keywords: Local binary pattern (LBP), orthogonally combined LBP (OC-LBP), radial orthogonal median LBP (ROM-LBP), local feature, feature compaction, classification.
1 Introduction
In last two decades local descriptors [1–3] have shown significant improvements with respect to the application they were developed. Local descriptors have gone from strength to strength during the passing years. In local descriptors, the methodology is deployed on small image patches to develop its feature size. Extracting features from different image regions make local descriptors much effective than global descriptors [4–6]. In global descriptors, methodology is deployed on the entire image. The challenges which persist on images are light, emotion, pose, age, noise, blur, corruptions and occlusions. In presence of these challenges the feature extraction algorithm will be implemented. Because of extracting the features from different regions local descriptors tends to produce bigger size. To make more robust and discriminant feature the global descriptors are very useful. When global descriptors are used as dimension reduction then it increases the accuracy of the local descriptors in most of the occasions.
Among numerous local descriptors invented in literature the one which received the most attention is Local Binary Pattern (LBP) [7]. LBP was developed for the Texture Analysis (TA) and later on it was successfully presented in the other application also. The reason behind LBP success is monotonic invariance (gray) protocol and less complex method. LBP also noticed some of the demerits and these are large dimension feature size, restrict its ability to single scale, missing the macrostructure information and performance decay in harsh lightning variations. All these demerits gives the scope of the further research to be conducted. As a results numerous LBP variants has been launched in literature and some of them achieved good results. Out of all the discussed demerits the one which remains the major problem is the performance decay in harsh lightning variations.
LBP and majority of its variants performs extremely well in front of moderate light variations. But when light variations becomes severe then performance of LBP and its variants are not satisfactory. Therefore there is a need of the more promising and impressive descriptor which performs well in the harsh light variations.
Contributions: To complement these LBP based descriptors the proposed work launches the novel descriptor for Face Recognition (FR) in harsh lightning variations. This proposed descriptor is called as Radial Orthogonal Median LBP (ROM-LBP). The main demerit of these LBP based descriptors is that they all consider uniform coordination between neighbors and center pixel. Which mean raw pixel intensity is used for comparison with center pixel. The proposed work eliminates this problem in the introduced descriptor ROM-LBP, by replacing the raw pixels intensity with the median of the radial points in each orthogonal position of the two separate groups. The generated median is then used for comparison with the center pixel. The respective codes obtained from both the groups are concatenated to form the ROM-LBP size. As region feature extraction is done therefore ROM-LBP develops the large feature size. To make more effective descriptor, the services of FLDA [8] is used and then classification was conducted by SVMs [9]. Experiments conducted on EYB [10] and YB [10] datasets demonstrates the ability of the proposed ROM-LBP against various LBP and non-LBP based descriptors.
Remaining paper is defined as: Related works are placed in Section 2, explanation of compared descriptors are posted in the Section 3, presented descriptor with framework are delivered in Section 4, experiments are furnished in Section 5 with conclusion and future scope are discussed in Section 6.
2 Related Works
Truong et al. [11] developed novel descriptor for Face Recognition (FR) so-called Weighted Statistical Binary Patterns (WSBP). In WSBP, there is utilization of straight line topology across distinct directions for developing feature size. Precisely, the input image is partitioned in variance and mean moments. A novel moment so-called variance is constructed by generating the k-th root. By utilizing mean moment, when sign and magnitude elements are generated across four distinct directions then as per the new variance the weighting method is deployed to every component. Finally the sign and magnitude element histograms are combined to form the entire feature size. On six face datasets WSBP shows its potency by defeating the accuracy of various state of art methods. Different local and global methods are outclassed by the WSBP. The demerits which are noticed in this work is that: the computational cost of the WSBP is on the higher side and second some much better global method can be used for feature compression. Wei et al. [12] proposed the LBP from Five Intersecting Planes (LBP-FIP) for micro expression recognition. In LBP-FIP, the LBP-TOP is integrated with EV-LBP to generate feature size. LBP-TOP features are derived from 3 planes and EV-LBP is generated from 2 planes in oblique orientation. As a result the dynamic features (texture) are generated more directly in oblique direction. On 2 datasets the LBP-FIP justify its efficacy. Compared to other LBP based methods the LBP-FIP proves out much dominant. The demerits which is noticed in this work is that lack of usage of the large dataset. The use of large dataset will explore the descriptor more appropriately. Karanwal et al. [13] proposed OD-LBP operator for FR. In OD-LBP, first 3 differences (gray) are extracted from every orthogonal location of the 3x3 patch. Then these differences (gray) are availed by the novel thresholding function for developing OD-LBP code. On numerous datasets OD-LBP proves its ability by defeating the accuracy of various others. The demerits which are observed in this work is that the multiscale feature is missing and some much better global method can be used for feature compression. Karanwal et al. [14] discovered the MB-ZZLBP descriptor for FR. In MB-ZZLBP, first mean filtration is done on 9 regions of 6x6 patch. After mean computation the 3x3 patch is produced. In 3x3 patch, the zigzag alignment of pixels are compared with each other. If the former one have greater or equal value to the latter pixel (as per the zigzag alignment) then label assigned is 1 otherwise 0. The evolved binary pattern is transfigured to MB-ZZLBP code by putting weights and summation of values. Experiments conducted on different datasets proves the strength of MB-ZZLBP. Compared to other techniques MB-ZZLBP proves out very effective in noise and illumination variations. The major concern which remains in MB-ZZLBP is the integration of the lower and the higher scale features. This integration will definitely improves the recognition accuracy.
Chaabane et al. [15] invented the novel FR by integrating the statistical features and SVM. For extracting the statistical features, the statistical analysis is conducted and then SVM method is used for joining and classification of the features. Experiments shows the accuracy of 99.37% on ORL face dataset. This method outperforms various other methods on ORL dataset. The major concern which remains is the testing on large scale dataset and using some other classifiers for enhancing the robustness. Chandrakala et al. [16] utilized the combination of HOG and LBP descriptor to attain the discriminant and robust FR. HOG captures the gradient details by using the 1D mask and LBP captures the local features. Experiments conducted on ORL dataset demonstrates capability of the invented method. The invented integrated method conquer the performance of the alone descriptor. Some of the key points which are missed in this work, is the comparison against the other state of art methods and second usage of the large dataset. Kar et al. [17] utilizes Blocked LBP (B-LBP) for Tropical Cyclone Analysis (TCA). LBP develops the code by describing the local structure in efficient and easy manner. The proposed B-LBP is the improved version of the LBP which compute center pixel from the input image. Precisely the image is partitioned into 3x3 regions (blocks) and then each block center pixel is utilized to develop a new pattern of image. This image is analysed further by histogram and box plot for classification. Experiments proves the capability of the B-LBP. The B-LBP method comprehensively beats the performance of the LBP method. But the issue which is noticed is the development of the large dimension feature size. Some global method can used for feature compression. Rasool et al. [18] presented the novel descriptor for TA so-called effective LBP. Precisely the computationally efficient and rotation invariant LBP has been proposed. The effective LBP considers the radial derivative and circumferential information to generate the feature size of effective LBP. Radial derivative minimizes computational cost as it is sensitive to the changes in radius. Furthermore circumferential and radial derivatives generate details along the center pixel of complementing nature. The integration of the radial and circumferential derivatives leads to effective and robust rotation invariant representation. Experiments proves efficacy. Under extreme light variations the performance of the effective LBP is not satisfactory.
Karanwal et al. [19] impose 2 novel descriptors in FR. These two descriptors are called as CZZBP and CMBZZBP. RGB format is used for generating color features. In CZZBP, the zigzag design is created for each component of RGB color format. Then as per zigzag design the features are extracted from the RGB color format. Then all three features (component) are joined to develop CZZBP size. The CZZBP features are extracted from the 3x3 patch. In CMBZZBP, initially median is computed from 9x9 patch and then concept of CZZBP is deployed. Both descriptor achieves stupendous results on different datasets. Compared to other descriptors both CZZBP and CMBZZBP achieves better results. Some of the concerns which are noticed in this work are: Some better color format can be used for feature extraction and second testing on large scale dataset. Vu et al. [20] developed the mask based FR by using LBP and Deep features. The Deep features are extracted by using RetinalFace, which is self-supervised and jointly extra-supervised learning detector (face) to deal with several faces at multiple scales. The LBP features are extracted from the elements of the masked face and these are foreheads, eyes and eyebrow locations. The extracted LBP features are joined with RetinalFace learned features to develop the unified framework. Experiments confirms the ability of the proposed method. The computational complexity of this method is very high. Raghuwanshi et al. [21] impose the Hybrid Directional Extrema Pattern (HDEP) for TA. Specifically the texture features are generated in four different directions and these are 0, 45, 90 and 135 degrees. HDEP considers difference among center and the neighbors in the specified direction. For next stage the difference is utilized as the weight. Then weight is compared with the threshold (used defined) for generating the strong bits value in the form of feature vector. Results on three datasets demonstrates the efficacy of the proposed HDEP. HDEP beats the performance of various local descriptors. But major demerit which is lacking is the usage of Deep learning method. The inclusion of Deep learning methods will definitely enhances the recognition rate. Ahuja et al. [22] presented the FR by using the combination of LBP and ELM. In LBP, the features are derived from distinct mic-regions and then all regions features are integrated to develop the entire image representation. Then ELM used for the classification which is fast and effective learning algorithm. Results on 2 face datasets demonstrates the effectiveness of the invented method. The development of large dimension feature size is the disadvantage of this method. No global method is used for feature compaction. Shanthi et al. [23] discovered the expression recognition by fusing LBP with LNEP. LBP captures the relationship between neighbors and the center pixel while LNEP represents the connection between two nearest neighbors of the current pixel. The integration of LBP and LNEP yields the huge size therefore Chi-square distance is utilized for picking relevant features. Finally classification was performed by SVMs. Experiments on different datasets proves the ability of fused method. Although the integration of LBP and LNEP proves out very effective and it outperforms various method. But usage of some better feature compaction method will definitely improves the recognition rates.
Karanwal et al. [24] provides the comparative analysis of 14 state of art descriptors. All 14 are LBP based descriptors. For all 14 descriptors the global histograms are extracted. Further the feature reduction is fulfilled by using the PCA and FLDA. Among all 14 it is CLBP which achieves the best outcomes. On some cases the MRELBP-NI achieves good results. Some demerits which are found in this work are: First regional feature extraction are missing. The regional feature extraction improves the recognition rate to huge extent and second some better global method can be used for feature compression. Karanwal et al. [25] presented COC-LBP for light changes. COC-LBP is enhancement of OC-LBP operator. In OC-LBP, the code is formed after orthogonal neighbors are compared with the center pixel. The demerit of OC-LBP is inclusion of only sign features (component). This restricts the robustness of OC-LBP. To eliminate this COC-LBP is proposed. In COC-LBP, magnitude features are formed and included with sign component features. Therefore COC-LBP yields much better accuracy than OC-LBP. COC-LBP outclasses various methods from literature. The issue which is noticed in COC-LBP is the multiscale feature extraction is missing.
The multiscale feature extraction definitely improves the recognition rates. Table 1 display the merits and demerits of the work reported in literature.
Table 1 The merits and demerits of the work reported in literature
| Techniques & | ||
| References | Merits | Demerits |
| WSBP [11] | Different local and global methods are outclassed by the WSBP. | Computational cost is on the higher side and some much better global method can be used for feature compression. |
| LBP-FIP [12] | Compared to the other LBP based methods the LBP-FIP proves out much dominant. | Lack of usage of large dataset. The use of large dataset will explore descriptor more. |
| OD-LBP [13] | OD-LBP is the effective methodology as a result it outperform various methods. | Multiscale feature extraction is missing and some much better global method can be used for feature compression. |
| MB-ZZLBP [14] | On noise and light variations the MB-ZZLBP proves out very impressive. | The major concern which remains in MB-ZZLBP is the integration of lower and higher scale features. This integration will surely improve recognition accuracy. |
| Statistical Features [15] | Achieves a stupendous ACC of 99.37% on ORL dataset. Defeating various methods. | The major concern which remains is the testing on large scale dataset and using some other classifiers for enhancing the robustness. |
| HOGLBP [16] | The integration of two local methods outperforms the performance of the alone methods. | Some of the key points which are missed in this work, is the comparison against the other state of art methods and second usage of the large dataset. |
| B-LBP [17] | Block feature extraction greatly improves accuracy and outperforms the other methods. | But the issue which is noticed is the development of the large dimension feature size. Some global method can used for feature compression. |
| Effective LBP [18] | Discriminant and Robust. Computational cost is on the lower side. | Under extreme light variations performance is not adequate. |
| CZZBP & CMBZZBP [19] | By using RGB color space format and three different zig zag designs the effective methodologies has been proposed, which outperform various methods. | Some better color format can be used for feature extraction and second testing on large scale dataset. |
| LBP + Deep features [20] | LBP features are extracted from the elements of masked face and these are foreheads, eyes and eyebrow locations. The extracted LBP features are joined with RetinalFace learned features to develop the unified framework. This framework proves very effective. | Computational complexity of this method is on higher side. |
| HDEP [21] | HDEP considers difference among center and neighbors in specified direction. As a result it outperforms various methods. | The deep learning method is missing. |
| LBPELM [22] | This combination proves out very fruitful compared to other state art methods. | The development of large dimension feature size is the disadvantage of this method. No global method is used for feature compaction. |
| LBPLNEP [23] | LBP captures relationship between neighbors and the center pixel while LNEP represents the connection between 2 nearest neighbors of current pixel. | Feature compression technique is not effective as it should be. Some better feature compaction technique can be utilized. |
| LBP based [24] | A comparative study is done for 14 state of art descriptors. Among all it is CLBP which attains best results. On some cased MRELBP-NI attains good results. | Regional feature extraction is missing. The regional feature extraction improves accuracy to huge extent and some better global method can be used for feature compression. |
| COC-LBP [25] | COC-LBP incorporates mag features with sign features, and it easily outperforms the OC-LBP accuracy & various others. | Multiscale feature extraction is missing. |
3 Explanation of Other Local Descriptors
3.1 Local Binary Pattern (LBP)
LBP [7] was initially presented for TA. Since then it has been effortlessly utilized in various applications. The monotonic invariance (gray) protocol and less complex method are some advantages of LBP. The definition of LBP is defined as: In LBP, intensity of neighbors are compared with intensity of center. If the neighbor’s intensity have substantially bigger or equal value to the center intensity then label allocated is 1. In remaining condition (i.e. less than) label 0 is assigned. From eight neighbors there is the formation of eight bit pattern (binary). The evolved pattern is transformed to LBP code by putting the binomial weights and the values summation. By calculating LBP code in every pixel spot of the image there is generation of LBP image. The LBP image is further partitioned in 3x3 regions for feature size making. Each region of LBP image develops the histogram size of 256 therefore from nine regions LBP complete size is 2304. The LBP formula is defined in Equation (1). In Equation (1) D, S, and portrays the limit (of neighbors), radius, sole neighbor spots and center intensity.
| (1) |
3.2 Horizontal Elliptical LBP (HELBP)
HELBP [26] was initially presented for FR. Since then it has been effortlessly utilized in various applications. Multi-scaling, monotonic invariance (gray) protocol, less complex method and robust are some advantages of HELBP. The definition of HELBP is defined as: In HELBP, intensity of eight horizontal neighbors are compared with intensity of center. If the neighbor’s intensity have substantially bigger or equal value to the center intensity then label allocated is 1. In remaining condition (i.e. less than) label 0 is assigned. From eight neighbors there is the formation of eight bit pattern (binary). The evolved pattern is transformed to the HELBP code by putting binomial weights and the values summation. By calculating the HELBP code in every pixel spot of image there is generation of HELBP image. The HELBP image is further partitioned in 3x3 regions for feature size making. Each region of HELBP image develops the histogram size of 256 therefore from nine regions HELBP complete size is 2304. The HELBP formula is defined in Equation (2). In Equation (2) D, , , and portrays the limit (of neighbors), radius , radius , sole neighbor places and center intensity.
3.3 Histogram of Oriented Gradients (HOG)
HOG [27] was presented initially for the human detection. Since then HOG was utilized successfully in several applications. HOG is gradient based descriptor. To produce the regional gradients, initially one dimensional mask [1 0 1] is used at standard deviation (). After testing numerous masks the authors of [27] have selected one dimensional mask. To represent these gradients in the form of histogram the bin size which is considered adequate is 9. In [27] it has been noticed that upto 9 bin size histogram the performance of the HOG doesn’t degrades but higher than that the performance falls rapidly. Therefore they stick to the bin size 9. To increase further discriminativity, two more steps are also conducted and these are feature overlapping and contrast normalization. Both these steps are accomplished in the bigger blocks of size axb. It is required to select the appropriate feature overlapping size as larger overlapping substantially increases the feature size. For contrast normalization four methods can be deployed and these are L2-hys, L1-sqrt, L1-norm and L2-norm.
In this work, HOG features are generated from each region of 3x3 partitioned image. For feature overlapping the 50% of HOG features are overlapped in blocks of size 2x2. Therefore after overlapping four 2x2 blocks are generated. 1 region (block) size is 9 therefore entire HOG size is .
3.4 Center Symmetric LBP (CS-LBP)
CS-LBP [28] was discovered originally for TA. Later on it was used successfully on other applications also. The short histogram feature size and providing robustness in the flat regions are the advantages of CS-LBP. The definition of CS-LBP is defined as: In CS-LBP, the gray difference derived among the center symmetric pixels are compared against the chosen threshold. If the difference possesses bigger value than the threshold then the label assigned is 1. In the remaining condition (i.e. less than or equal to the threshold) label 0 is assigned. This obtains the four bit pattern (binary). The evolved pattern is transformed to CS-LBP code by putting binomial weights and values summation. By calculating CS-LBP code in every pixel spot of image there is generation of CS-LBP image. The CS-LBP image is further partitioned in 3x3 regions for feature size making. Each region of CS-LBP image develops the histogram size of 16 therefore from nine regions CS-LBP complete size is 144. The CS-LBP formula is defined in Equation (3). In Equation (3) D, S, T, and are limit (of neighbors), radius, threshold and center symmetric pixels.
| (3) |
3.5 Orthogonally Combined LBP (OC-LBP)
OC-LBP [29] was discovered for the different applications. Later on it was used effortlessly on the other applications also. The advantages of OC-LBP are short histograms and discriminant in moderate light variations. The definition of OC-LBP is defined as: In OC-LBP, the intensity of orthogonal neighbors (in 3x3 patch) are compared with intensity of center. In OC-LBP there are two orthogonal groups and in each orthogonal group all the neighbor’s intensity are compared with the intensity of center. If the neighbor’s intensity have substantially bigger or equal value to the center intensity then label allocated is 1. In remaining condition (i.e. less than) label 0 is assigned. From each group there is the formation of four bit pattern (binary). The evolved pattern is transformed to OLBP1 and OLBP2 codes by putting binomial weights and values summation. By calculating OLBP1 and OLBP2 code in every pixel spot of the image there is generation of OLBP1 and OLBP2 images. These images are further partitioned in 3x3 regions for feature size making. Each region of both the image develops the histogram size of 16 therefore from nine regions of OLBP1 and OLBP2 the complete size generated is 144. Furthermore both OLBP1 and OLBP2 sizes are concatenated to develop the OC-LBP size. Therefore OC-LBP forms the size of 288. The OC-LBP formula is depicted in Equations (4), (5) and (6). In Equations (4) and (5) D, S, , and specifies limit (of neighbors), radius, sole neighbor places (in first orthogonal group), sole neighbor places (in second orthogonal group) and center intensity. Equation (6) concatenates both the codes.
| (4) | |
| (5) | |
| (6) |
4 The Proposed Descriptor with Complete FR Framework
4.1 Radial Orthogonal Median LBP (ROM-LBP)
LBP and majority of its variants performs unwell when lightning variations are severe. Additionally most of these LBP based descriptors provide uniform correlation between the neighbors and center pixel. As a result the achieved discriminativity is not as impressive as it is required in lightning variations. To fill this gap, the proposed work introduces novel descriptor ROM-LBP in harsh light variations. It has been noticed that if median filter is used in the radial neighborhood before extracting features then there is much better enhancement in classification accuracy as compared to most of LBP based descriptors. The detailed description of ROM-LBP is defined from next paragraph.
The initially step in ROM-LBP is to take 7x7 patch for feature extraction. Then 7x7 patch is partitioned in two groups of orthogonal patches. Only orthogonal pixels are retained in both the groups and rest others are removed. In both groups the radial medians are computed for all four positions of both the groups. For set of three radial pixels the medians are generated in all the positions. After median computation two 3x3 patch produced and in each patch there are four orthogonal pixels with the center pixel. In other words it can be said that the original raw pixels are replaced by the median of those. Now in each orthogonal group all the neighbor’s intensity are compared with the intensity of the center pixel. If the neighbor’s intensity have substantially bigger or equal value to the center intensity then label allocated is 1. In remaining condition (i.e. less than) label 0 is assigned. From each group there is the formation of four bit pattern (binary). The evolved pattern is transformed to ROM-LBP1 and ROM-LBP2 codes by putting binomial weights and values summation. By calculating ROM-LBP1 and ROM-LBP2 code in every pixel spot of the image there is generation of ROM-LBP1 and ROM-LBP2 images. These images are further partitioned in 3x3 regions for feature size making. Each region of both the image develops the histogram size of 16 therefore from nine regions of ROM-LBP1 and ROM-LBP2 the complete size generated is 144. Furthermore both ROM-LBP1 and ROM-LBP2 sizes are concatenated to develop the ROM-LBP size. Therefore ROM-LBP forms the size of 288. ROM-LBP concept is defined in Equations (7)–(11). In Equations (7) and (9) D and S are limit (of neighbors) and radius and is the center pixel. forms median value from pixels. In Equations (8) and (10) is individual radial points in 4 orientations of the respective orthogonal patches. Equation (11) concatenate both codes. Figure 1 shows ROM-LBP example.
| (7) | |
| (8) | |
| (9) | |
| (10) | |
| (11) |
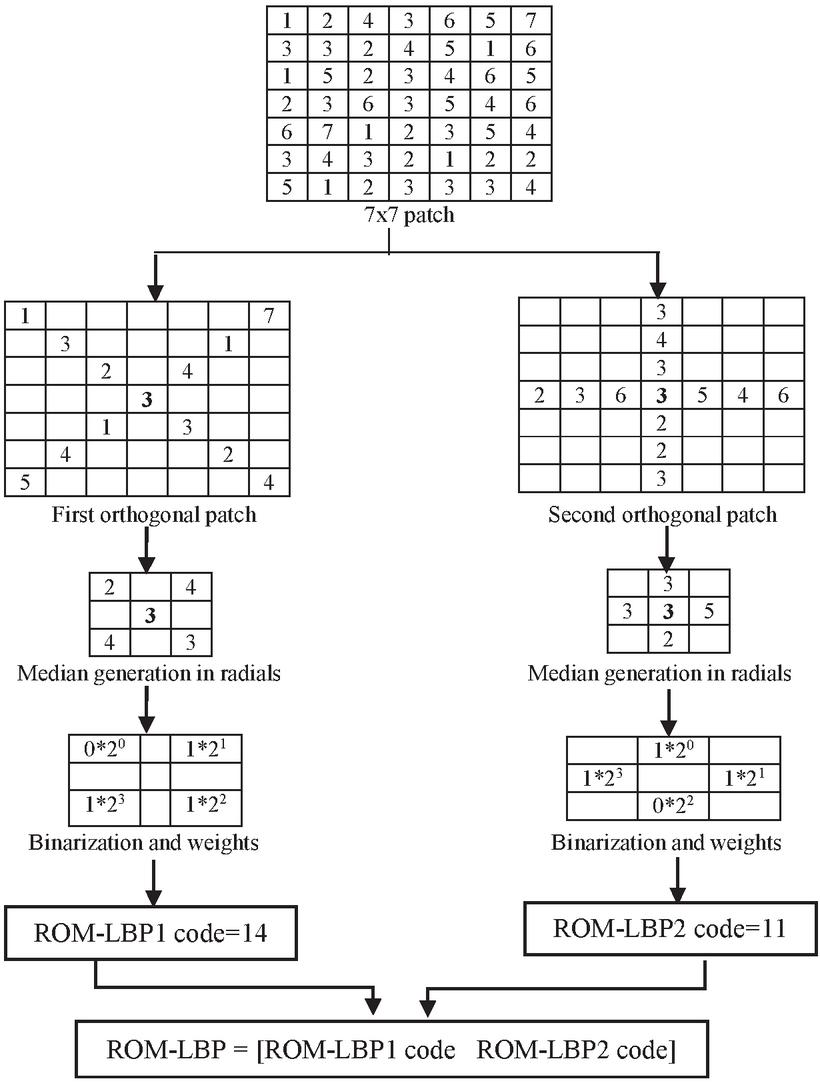
Figure 1 ROM-LBP example.
4.2 The Proposed FR Framework
ROM-LBP feature size is on higher side as regional features are extracted. To bring more robust and discriminant feature for classification, the sub-space technique FLDA is used. FLDA is effective and impressive dimension reduction technique therefore it is utilized. The compact feature is then consumed by RBF classifier (SVM technique) for accuracy evaluation. Figure 2 declare complete proposed FR framework. The steps of feature compression and classification are also performed on compared descriptors.
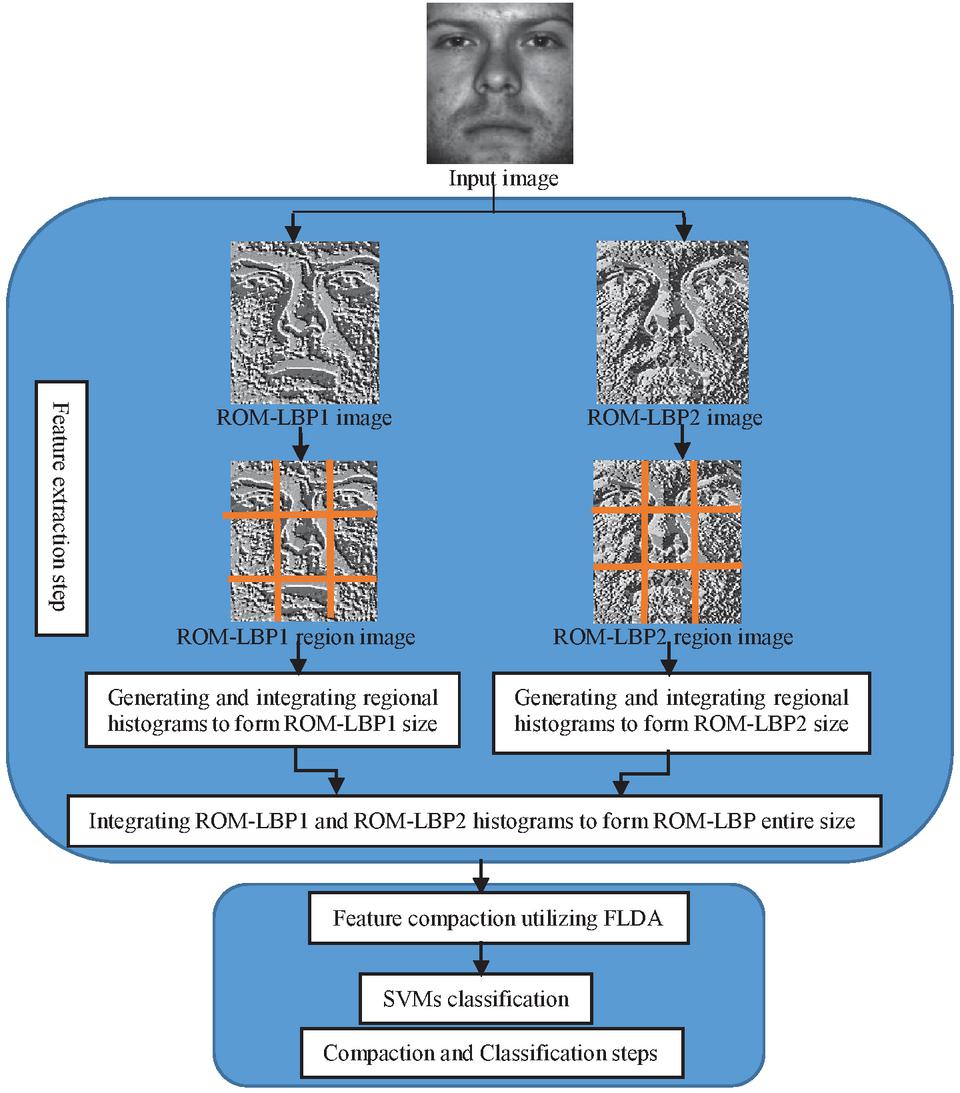
Figure 2 Entire FR framework.
5 Experiments
5.1 Datasets Illustration
The illustration of two datasets consumed for the evaluation are as defined. First dataset utilized is EYB. EYB is made up of 38 human beings under the challenge light variations. Precisely 2432 images of 38 human beings are acquired in 64 light variations. Some of the light variations are so diverse that it becomes very difficult to recognize them. All the images are posed in frontal alignment and have resolution of 192x168. 18 images becomes unused (corrupts) in formation of the dataset, which sets total to 2414. For FLDA compaction the PCA is conducted on 2414 samples and for LDA compression the zero bit padding is done for those samples which are corrupted. Some samples of EYB are declared in Figure 3(a).
Second dataset utilize is YB. YB is made up of 10 human beings under the challenge light variations. Precisely 5760 images of 10 humans are acquired in 64 light variations under 9 poses. Furthermore 1 ambient image is also captured, which sets the total to 5850. For this work frontal posed images are utilized for the evaluation. Which means 650 images are used. Some samples of YB are declared in Figure 3(b).

Figure 3 Some samples.
5.2 Essentials Pertaining to Feature Size
Even the cropped versions of both EYB and YB is available. But still the feature size is on the higher side. Therefore there is need to cut the feature size so that the computational cost is on the lower side. So to achieve that the cropped size is further resized to 48x42. From 48x42 size, 6 descriptors are evaluated for feature extraction and these are LBP, HELBP, HOG, CS-LBP, OC-LBP and ROM-LBP. The ROM-LBP is the proposed descriptor. For all of them regional histograms are extracted and fused. The feature size derived from these are 2304, 2304, 144, 144, 288 and 288. To make more effective and discriminant feature size FLDA is deployed to all of them. So after deploying FLDA the size produced are [128 24] and [134 16] on EYB and YB datasets. In square brackets the first size pertains to the PCA and second size pertains to the LDA. Second size is consumed by the RBF for evaluation. The environment in which all testing and coding was performed is MATLAB R2021a.
5.3 Accuracy Estimation on Various Subsets
To estimate accuracy on different subsets, the protocol/formula is defined in Equation (12). In Equation (12), the three ingredients are utilized and these are ACC, and . ACC defines the accuracy, states the test data set and defines incorrect matched samples. The remaining ingredient specifies the training dataset.
| (12) |
On EYB, the , 10, 20, 32 and , 54, 44, 32. Ratio wise these subsets are 5/59, 10/54, 20/44 and 32/32. It means that when 5 samples per human are reserved for training then 59 are used for testing for the first subset. For second subset 10 samples per human are preserved for training and rest 54 are reserved for testing. Similarly the third and fourth subsets are formed. On each subset the finest ACC is measured after classifier performs 30 executions. Table 2 shows the ACC analysis on EYB dataset. Table 2 shows that ROM-LBP (the proposed descriptor) conquers the ACC of all 5 compared descriptors on all subsets. ROM-LBP attains the ACC of [96.92% 97.70% 98.62% 98.84%] on , 10, 20, 32. These ACC’s are much higher and super than other compared descriptors. The ACC margin among ROM-LBP and compared descriptors is phenomenal. The maximum ACC difference is between ROM-LBP and HOG i.e. 21.23%. ACC obtained through graph is shown in Figure 4(a).
On YB, the , 2, 3, 5 and , 63, 62, 60. Ratio wise these subsets are 1/64, 2/63, 3/62 and 5/60. It means that when 1 samples per human is reserved for training then 64 are used for testing for first subset. For second subset 2 samples per human are preserved for training and rest 63 are reserved for testing. Similarly the third and fourth subsets are formed. On each subset the finest ACC is measured after classifier performs 20 executions. Table 3 shows the ACC analysis on YB dataset. Table 3 shows that ROM-LBP (the proposed descriptor) conquers the ACC of all 5 compared descriptors on all subsets. ROM-LBP attains the ACC of [92.18% 99.21% 99.67% 100%] on , 2, 3, 5. These ACC’s are much higher and super than other compared descriptors. The ACC margin among ROM-LBP and the compared descriptors is phenomenal. The maximum ACC difference is between ROM-LBP and HOG i.e. 40.62%. ACC obtained through graph is shown in Figure 4(b).
Table 2 ACC achieved on EYB
| TG Attributes | ||||
| TG | TG | TG | TG | |
| Descriptors | ACC | |||
| LBP | 118/94.73 | 71/96.53 | 47/97.18 | 24/98.02 |
| HELBP | 104/95.36 | 65/96.83 | 37/97.78 | 23/98.10 |
| HOG | 545/75.69 | 420/79.53 | 280/83.25 | 180/85.19 |
| CS-LBP | 266/88.13 | 171/91.66 | 83/95.03 | 54/95.55 |
| OC-LBP | 112/95.00 | 65/96.83 | 45/97.30 | 23/98.10 |
| ROM-LBP | 69/96.92 | 47/97.70 | 23/98.62 | 14/98.84 |
Table 3 ACC achieved on EYB
| TG Attributes | ||||
| TG | TG | TG | TG | |
| Descriptors | /ACC | |||
| LBP | 95/85.15 | 17/97.30 | 08/98.70 | 03/99.50 |
| HELBP | 71/88.90 | 15/97.61 | 07/98.87 | 02/99.66 |
| HOG | 310/51.56 | 164/73.96 | 146/76.45 | 85/85.83 |
| CS-LBP | 156/75.62 | 43/93.17 | 22/96.45 | 10/98.33 |
| OC-LBP | 98/84.68 | 17/97.30 | 06/99.03 | 02/99.66 |
| ROM-LBP | 50/92.18 | 05/99.21 | 02/99.67 | 00/100 |
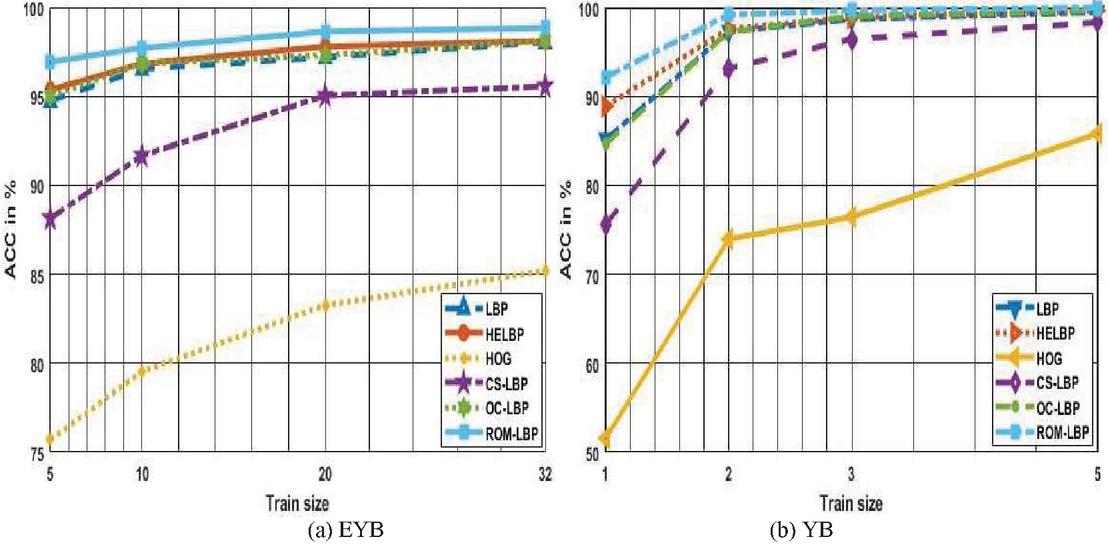
Figure 4 ACC illustration through graph.
5.4 Accuracy Comparison with Literature Techniques
Numerous methods from literature are picked and utilized for comparison. Their protocols might be different for implementation but they are tested on same values on which the proposed descriptor is tested. The prime motive is to compare these techniques on the same values.
5.4.1 EYB dataset
On EYB, 19 techniques are picked and compared with ROM-LBP. The detailed description of these are as follows: HO-GCNMR [30], KFME [30], ELD [32], CLBP [32], MBP [24], 6x6 MB-LBP [24] and ELBP [24] attain the ACC of 90.60%, 86.10%, 90.72%, 81.57%, 52.75%, 69.25% and 68.77% on . RSLP [31], SparseFME [31] and SLP [31] procure the ACC of 93.63%, 89.91% and 91.00% when . 2D-DWTLBP [33], 2D-DWTHELBP [33], ESLLE [34] and SLLE [34] secure the ACC of [68.20% 74.04% 80.20%], [67.70% 74.80% 79.40%], [39.89% 55.27% 67.64%] and [38.16% 49.98% 63.69%] when , 10 & 20. DRR [35], Deep learning [35], MWEE-C [36], MEESRC [36] and HQ [36] attain the ACC of 90.00%, 92.00%, 99.80%, 96.50% and 95.70% on . The proposed ROM-LBP outstrip the ACC of 18 techniques completely. One technique which appears to be better than ROM-LBP is MWEE-C [36]. Table 4 delivers all the ACC analysis.
Table 4 ACC comparison on EYB
| TG Details | ||||
| TG | TG | TG | TG | |
| Techniques | ACC in % | |||
| HO-GCNMR [30] | NA | NA | 90.60 | NA |
| KFME [30] | NA | NA | 86.10 | NA |
| RSLP [31] | NA | 93.63 | NA | NA |
| SparseFME [31] | NA | 89.91 | NA | NA |
| SLP [31] | NA | 91.00 | NA | NA |
| ELD [32] | NA | NA | 90.72 | NA |
| CLBP [32] | NA | NA | 81.57 | NA |
| 2D-DWT+LBP [33] | 68.20 | 74.04 | 80.20 | NA |
| 2D-DWT+HELBP [33] | 67.70 | 74.80 | 79.40 | NA |
| ESLLE [34] | 39.89 | 55.27 | 67.64 | NA |
| SLLE [34] | 38.16 | 49.98 | 63.69 | NA |
| DRR [35] | NA | NA | NA | 90.00 |
| Deep learning [35] | NA | NA | NA | 92.00 |
| MWEE-C [36] | N/A | N/A | N/A | 99.80 |
| MEESRC [36] | N/A | N/A | N/A | 96.50 |
| HQ [36] | N/A | N/A | N/A | 95.70 |
| MBP [24] | N/A | N/A | 52.75 | N/A |
| 6x6 MB-LBP [24] | N/A | N/A | 69.25 | N/A |
| ELBP [24] | N/A | N/A | 68.77 | N/A |
| ROM-LBP | 96.92 | 97.70 | 98.62 | 98.84 |
| NA-Not Available | ||||
Table 5 ACC comparison on YB
| TG Details | ||||
| TG | TG | TG | TG | |
| Techniques | ACC in % | |||
| 2D-DWT+LBP [33] | N/A | N/A | N/A | 93.66 |
| 2D-DWT+HELBP [33] | N/A | N/A | N/A | 93.66 |
| 2D-DWT+MBP [33] | N/A | N/A | N/A | 92.50 |
| LC-LBP [24] | N/A | N/A | N/A | 85.16 |
| MRELBP-NI [24] | N/A | N/A | N/A | 93.00 |
| tLBP [24] | N/A | N/A | N/A | 88.66 |
| HELBP [37] | 88.12 | 97.77 | 98.70 | N/A |
| HE-ICA [38] | 72.00 | N/A | N/A | N/A |
| None-ICA [38] | 65.60 | N/A | N/A | N/A |
| NCDB-LBPac [39] | 98.28 | N/A | N/A | N/A |
| NCDB-LBPac [39] | 97.65 | N/A | N/A | N/A |
| ROM-LBP | 92.18 | 99.21 | 99.67 | 100 |
| NA-Not Available | ||||
5.4.2 YB dataset
On YB, 11 techniques are picked and compared with ROM-LBP. The detailed description of these are as follows: 2D-DWT+LBP [33], 2D-DWT+HELBP [33], 2D-DWT+MBP [33], LC-LBP [24], MRELBP-NI [24] and tLBP [24] attain the ACC of 93.66%, 93.66%, 92.50%, 85.16%, 93.00% and 88.66% when . HELBP [37] secures the ACC of [88.12%, 97.77% 98.70%] when :3. HE-ICA [38], None-ICA [38], NCDB-LBPac [39] and NCDB-LBPc [39] secured the ACC of 72.00%, 65.60%, 98.28% and 97.65% on . The proposed ROM-LBP outstrip ACC of 9 techniques entirely. The 2 techniques which proves better than ROM-LBP are NCDB-LBPac [39] and NCDB-LBPc [39]. Table 5 shows all the comparison.
6 Conclusion with Future Scope
The proposed work launches the novel descriptor for Face Recognition (FR) in harsh lightning variations so-called Radial Orthogonal Median LBP (ROM-LBP). The main demerit of these LBP based descriptors is that they all consider the uniform coordination between the neighbors and center pixel. Which mean raw pixel intensity is used for the comparison with the center pixel. The proposed work eliminates this problem in the introduced descriptor ROM-LBP, by replacing the raw pixels intensity with the median of the radial points in each orthogonal position of the two separate groups. The generated median is then used for comparison with the center pixel. The respective codes obtained from both the groups are concatenated to form the ROM-LBP size. As region feature extraction is done therefore ROM-LBP develops the large feature size. To make more effective descriptor, the services of FLDA is used and then classification was conducted by SVMs. Experiments conducted on EYB and YB datasets demonstrates the ability of the proposed ROM-LBP against various LBP and non-LBP based descriptors.
There are several ways of extending the proposed work to the futuristic research. First testing of the proposed descriptor on other challenges such as noise, blur, occlusions and corruptions. Second, implementation of proposed descriptor on different cases such as the object recognition, palmprint recognition, ear recognition, scene classification, texture analysis etc. Third the proposal of more discriminant local descriptor in unconstrained conditions. All these important points will be accomplished in upcoming research.
References
[1] Zhang, Z., and Wang, M. (2022). Multi-feature fusion partitioned local binary pattern method for finger vein recognition. Signal Image and Video Processing.
[2] Jaffino, G., Sundaram, M., and Jose, J.P. (2022). Weighted 1D-local binary pattern features and Taylor-Henry gas solubility optimization based Deep Maxout network for discovering epileptic seizure using EEG. Digital Signal Processing, 122.
[3] Singh, A., Sunkaria, R.K., and Kaur, A. (2022). A Review on Local Binary Pattern Variants. In: Proceedings of the First International Conference on Computational Electronics for Wireless Communications (pp. 545–552).
[4] Zhu, F., Gao, J., Yang, J., and Ye, N. (2021). Neighborhood linear discriminant analysis. Pattern Recognition, 123, 1–9.
[5] Liu, T., Yang, Z., Marino, A., Gao, G., and Yang, J. (2022). Joint Polarimetric Subspace Detector Based on Modified Linear Discriminant Analysis. IEEE Transactions on Geoscience and Remote Sensing.
[6] Gang, A., and Bajwa, W.U. (2022). A Linearly Convergent Algorithm for Distributed Principal Component Analysis. Signal Processing.
[7] Ojala, T., Pietikainen, M., and Harwood, D. (1996). A comparative study of texture measures with classification based on featured distributions. Pattern Recognition, 29(1), 51–59.
[8] Rajabzadeh, H., Jahromi, M.Z., and Ghodsi, A. (2021). Supervised discriminative dimensionality reduction by learning multiple transformation operators. Expert Systems with Applications, 164, 1–10.
[9] Hazarika, B.B., Gupta, D. (2021). Density-weighted support vector machines for binary class imbalance learning. Neural Computing and Applications, 33, 4243–4261.
[10] Georghiades, A.S., Belhumeur, P.N., and Kriegman, D.J. (2001). From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose. IEEE Transactions on Pattern Analysis & Machine Intelligence, 23(6), 643–660.
[11] Truong, H.P., Nguyen, T.P., and Kim, Y.G. (2022). Weighted statistical binary patterns for facial feature representation. Applied Intelligence, 52, 1893–1912.
[12] Wei, J., Lu, G., Yan, J., and Liu, H. (2022). Micro-expression recognition using local binary pattern from five intersecting planes. Multimedia Tools and Applications.
[13] Karanwal, S., and Diwakar, M. (2021). OD-LBP: Orthogonal difference Local Binary Pattern for Face Recognition. Digital Signal Processing, 110.
[14] Karanwal, S., and Diwakar, M. (2022). MB-ZZLBP: Multiscale Block ZigZag Local Binary Pattern for Face Recognition, In: Machine Learning, Advances In: Computing, Renewable Energy and Communication (pp. 613–622).
[15] Chaabane, S.B., Hijji, M., Harrabi, R., and Seddik, H. (2022). Face recognition based on statistical features and SVM classifier. Multimedia Tools and Applications, 81, 8767–8784.
[16] Chandrakala, M., and Devi, P.D. (2022). Face Recognition Using Cascading of HOG and LBP Feature Extraction. In: International Conference on Soft Computing and Signal Processing (pp. 553–562).
[17] Kar, C., and Banerjee, S. (2021). Tropical Cyclones Classification from Satellite Images Using Blocked Local Binary Pattern and Histogram Analysis. In: Soft Computing Techniques and Applications (pp. 399–407).
[18] Rasool, M., and Kaur, A. (2021). A Novel Rotation Invariant Descriptor for Texture Classification with Local Binary Patterns. In: Soft Computing and Signal Processing (pp. 385–396).
[19] Karanwal, S., and Diwakar, M. (2021). Two novel color local descriptors for face recognition. Optik. 226.
[20] Vu, H.N., Nguyen, M.H., and Pham, C. (2022) Masked face recognition with convolutional neural networks and local binary patterns. Applied Intelligence. 52, 5497–5512.
[21] Raghuwanshi, G., and Tyagi, V. (2021). Texture image retrieval using hybrid directional Extrema pattern. Multimedia Tools and Applications. 80, 2295–2317.
[22] Ahuja B., and Vishwakarma, V.P. (2021). Local Binary Pattern Based ELM for Face Identification. In: Proceedings of International Conference on Artificial Intelligence and Applications (pp. 363–369).
[23] Shanthi, P., and Nickolas, S. (2021). An efficient automatic facial expression recognition using local neighborhood feature fusion. Multimedia Tools and Applications, 80, 10187–10212.
[24] Karanwal, S. (2021). A comparative study of 14 state of art descriptors for face recognition. Multimedia Tools and Applications, 80, 12195–12234.
[25] Karanwal, S. (2021). COC-LBP: Complete Orthogonally Combined Local Binary Pattern for Face Recognition. In: 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON) (pp. 534–540).
[26] Nguyen, H.T., and Caplier, A. (2012). Elliptical Local Binary Patterns for Face recognition. In: Asian Conference on Computer Vision (pp. 85–96).
[27] Dalal, N., and Triggs, B. (2005) Histograms of oriented gradients for human detection. In: Proceedings of Computer Vision and Pattern Recognition (pp. 886–893).
[28] Heikkila, M., Pietikainen, M., and Schmid, C. (2009). Description of interest regions with local binary patterns. Pattern Recognition, 42(3), 425–436.
[29] Zhu, C., Bichot, C.E., and Chen, L. (2013). Image region description using orthogonal combination of local binary patterns enhanced with color information. Pattern recognition, 46(7), 1949–1963.
[30] Dornaika, F. (2022). On the use of high-order feature propagation in Graph Convolution Networks with Manifold Regularization. Information Sciences, 584, 467–478.
[31] Hua, Z., and Yang, Y. (2022). Robust and sparse label propagation for graph-based semi-supervised classification. Applied Intelligence, 52, 3337–3351.
[32] Karanwal, S. (2021). An Enhanced Local Descriptor (ELD) for Face Recognition. In: Proceedings of the Third International Conference on Inventive Research in Computing Applications.
[33] Karanwal, S. (2021). Improved LBP based Descriptors in Harsh Illumination Variations For Face Recognition. In: Proceedings of the International Arab Conference on Information Technology.
[34] Zhang, S. (2009). Enhanced supervised locally linear embedding. Pattern Recognition Letters, 30, 1208–1218.
[35] Li, H., and Suen, C.Y. (2016). Robust face recognition based on dynamic rank representation. Pattern Recognition, 60, 13–24.
[36] s Li, Y., Zhou, J., Tian, J., Zheng, X., and Tang, Y.Y. (2021). Weighted Error Entropy-Based Information Theoretic Learning for Robust Subspace Representation. IEEE Transactions on Neural Networks and Learning Systems, 1–15.
[37] Karanwal, S., and Diwakar, M. (2022). Improved ELBP descriptors for face recognition. International Journal of Computational Science and Engineering, 25(2), 198–210.
[38] Xie, X., and Lam, K.M. (2006). An efficient illumination normalization method for face recognition. Pattern Recognition Letters. 27, 609–617.
[39] Karanwal, S., and Diwakar, M. (2021). Neighborhood and center difference-based-LBP for face recognition. Pattern Analysis and Applications, 24, 741–761.
Biographies

Shekhar Karanwal achieved his B.Tech. in CS & IT from IET MJP Rohilkhand University, Bareilly, India. He obtained his M.E. in CSE from PEC University of Technology, Chandigarh, India. Currently he is pursuing Ph.D. (Full Time) in CSE Dept. from Graphic Era Deemed to be University, Dehradun, Uttarakhand, India. His research interests include Image processing, Pattern recognition, Computer vision and Biometrics.

Manoj Diwakar received his B.Tech. from Dr. R. M. L. Awadh University, Faizabad and M.Tech. from MITS, Gwalior, India. He completed his Ph.D. from BBAU, Lucknow, India in CS Department. Presently he is the Associate Professor in CSE Dept., Graphic Era Deemed to be University, Dehradun, Uttarakhand, India. His research areas are Image processing, Computer graphics and Information security.
Journal of Graphic Era University, Vol. 10_2, 155–180.
doi: 10.13052/jgeu0975-1416.1026
© 2022 River Publishers